
Sensei
Senior Members
-
Joined
-
Last visited
Everything posted by Sensei
-
You’ve realized by now that it’s “Science Forum Net” and not “Crap Forum Net”… right?
-
...because they are not planets... ?
-
This is ChatGPT-generated CUDA (nVidia GPUs only) for prime testing: #include <stdio.h> #include <math.h> // Kernel function to check if numbers are prime __global__ void checkPrimes(int *numbers, int *results, int n) { int idx = blockIdx.x * blockDim.x + threadIdx.x; // Make sure we don't go out of bounds if (idx < n) { int num = numbers[idx]; // Assume number is prime if (num < 2) { results[idx] = 0; return; } int isPrime = 1; // Check divisibility up to sqrt(num) for (int i = 2; i <= sqrt((float)num); i++) { if (num % i == 0) { isPrime = 0; break; } } results[idx] = isPrime; } } int main() { const int N = 10; int h_numbers[N] = {2, 3, 4, 5, 16, 17, 19, 20, 23, 24}; int h_results[N]; int *d_numbers, *d_results; // Allocate memory on GPU cudaMalloc((void**)&d_numbers, N * sizeof(int)); cudaMalloc((void**)&d_results, N * sizeof(int)); // Copy data from host to device cudaMemcpy(d_numbers, h_numbers, N * sizeof(int), cudaMemcpyHostToDevice); // Define block and grid sizes int threadsPerBlock = 256; int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock; // Launch kernel checkPrimes<<<blocksPerGrid, threadsPerBlock>>>(d_numbers, d_results, N); // Copy results back to host cudaMemcpy(h_results, d_results, N * sizeof(int), cudaMemcpyDeviceToHost); // Print results for (int i = 0; i < N; i++) { printf("%d is %s\n", h_numbers[i], h_results[i] ? "prime" : "not prime"); } // Free GPU memory cudaFree(d_numbers); cudaFree(d_results); return 0; }Compilation: nvcc prime_cuda.cu -o prime_cuda ./prime_cudaSome things are not possible on GPU (like calling operating system function, network connection, disk access or other hardware etc), but calculating prime numbers, is not one of them.. What Trurl wants is pretty simple and easy (see, I just asked ChatGPT and voila). But the weakness is only he.. This code should work on any nVidia with CUDA even for $20. Download nVidia CUDA Compiler from: https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/ CPU is a supervisor programming GPUs. Sending data, and receiving ready result. Search net for your gfx card model + "cuda cores" => you will know what approximate speed increase to expect from it vs CPU cores/threads. ChatGPT made stupid mistake which will slow down this code. Good I noticed. Fixed part: float limit = sqrtf((float)num); for (int i = 2; i <= limit; i++) { if (num % i == 0) { isPrime = 0; break; } }Otherwise sqrt() is called every iteration.. ps. @Trurl what GFX card do you have in your Xeon workstations.. ? Do they have slots for PCI-Express or so.. ? nVidia card for $20 has 384 cores, for $100 has 960-1024 CUDA cores. No need to buy some expensive monster just to make tests. Compile code and test, benchmark it. When you will see it works and has sense, and you need more video ram and more speed, you will invest more money in it.
-
Training your own LLM on your home computer has very little sense. You have ChatGPT. Deepseek. Gemini etc. What for training your own? It won't be comparable to the available engines.. i.e. will make even more errors.. Training ChatGPT takes from a few months to a year. On a >= 30k GPU cards.. What can you do with your single machine? When you are at this, you can try projects from https://huggingface.co/ It is kinda like "github for LLM". LLM won't change this. Even if you will train your own LLM on your own hardware. It will not give answers which were not already inside of training material. It won't give you unknown yet magic mathematical formulas, nor it won't give you a new physical equations and theories etc. Simply forget about such ridiculous tasks.. I have a discussion with ChatGPT about writing algorithm of finding patterns in a number. i.e. you don't need to go from 2...sqrt(333) to find that 333 is dividable by 111 (or 3), just because there is visible pattern in this number straight away. But it is visible for human, not to computer / algorithm. Pattern in decimal system, won't be visible in binary or hexadecimal system, and vice versa. So, instead of a brute-force algorithm, find a pattern in a number, and you know it is not a prime. If pattern is not easily visible, do brute force method to be sure. Did you try to write probabilistic primary tests in C/C++? https://en.wikipedia.org/wiki/Miller%E2%80%93Rabin_primality_test
-
That depends on which Xeon you bought and when.. But Xeon with 6 cores sounds now outdated and for $800 actually too much. Find you Xeon on cpubenchmark.net and link it here. For example, Intel Xeon E5-2660 @ 2.20GHz , Cores: 8 Threads: 16: https://www.cpubenchmark.net/cpu.php?cpu=Intel+Xeon+E5-2660+%40+2.20GHz&id=1219 has rank 8074. It is ~ 14% (1/7) of the best Mac laptop on the world (because M5 has rank 58514). Two such Xeons, and it is 1/4 of the best Mac laptop on the world. But, refurbished such CPU (because it is too old, not produced anymore), I have here for.. 8 USD. For it, obviously you need special mobo, and it can be some money, but it is still 94 USD (HP Proliant DL380p G8 732143-001 Dual Socket LGA2011 Server) You add to it 2x coolers and some old gfx (for a start), a lot of memory. One chip for 8 USD. 24 slots x 8 USD = 192 USD. 4GB x 24 = 96 GB RAM. Price about 8x2+94+192= 300 USD so far.. and it is just because I maxed DDR3 slots ;) Operating systems decide for any program, since ever, which thread runs on which core. And they switch with time, so no core is 100% and other cores 0% idle. It is because one would overheat and other don't. User or program can set up "Affiliate". You can do it, again, since ever, even on Windows XP, if I recall correctly, inside of Task Manager. This one you can force one specific process to use one specific core. But you don't want to do it without a good reason i.e. program is obsolete and does not work well on multi-threaded CPUs. I think they simply meant that instead of specifying the number of threads by human, it is read from CPU info, and the same thread count is used, so each thread (in programming sense) runs on each thread (in CPU sense, so sometimes it means core). Simply ask ChatGPT to generate it: #include <iostream> #include <thread> int main() { // Get the number of hardware-supported threads (logical cores) unsigned int threadCount = std::thread::hardware_concurrency(); std::cout << "Available threads: " << threadCount << std::endl; return 0; }(don't ask ChatGPT too much in a single request, ask for a one simple logic block, at this it is OK) Usage: #include <thread> #include <vector> int main() { // Get hardware thread count unsigned int n = std::thread::hardware_concurrency(); // Fallback in case the value is not available if (n == 0) n = 4; std::vector<std::thread> threads; for (unsigned int i = 0; i < n; ++i) { threads.emplace_back([]() { // Work to be done in each thread }); } // Join all threads for (auto& t : threads) { t.join(); } return 0; }I compiled it with g++ src.cpp -o dst and both worked fine. You do your heavy computation inside of emplace_back() 2x machines 2x cpus 6x = 24 cores for me ;) And they probably have 2x threads = so 48 threads all total. That's a very good machine for mathematician or 3D graphician or simply game player.. ;) But you need to split work wisely for threads. And have network communication between machines, so they tell each other what range of values they crunch etc. If it is meant to primes, it can be pretty simple, 1st machine does only primes-to-be with last digit 1 and 3, and 2nd machine does only 7 and 9 (or 1 & 7, 3 & 9). We can safely exclude 2,4,6,8 and 5,0 for obvious reasons. You can set some environment variable with value 1 and 2 on the other, then read it inside of C++ code, and from this crunch different ranges (so no actual network communication is needed, it could be hard for you). ChatGPT generated: #include <cstdlib> #include <string> // Get integer value from environment variable // Returns defaultValue if variable is missing or invalid int getEnvInt(const char* name, int defaultValue) { // Try to get environment variable if (const char* val = std::getenv(name)) { try { // Convert string to integer return std::stoi(val); } catch (...) { // Conversion failed (invalid format, overflow, etc.) } } // Return default if not found or conversion failed return defaultValue; } #include <iostream> int main() { int machine = getEnvInt("MACHINE", 0); std::cout << "Machine: " << machine << std::endl; }Set environment variable on each machine to a different value, then in code read it and voila, they crunch different ranges.
-
https://en.wikipedia.org/wiki/Glass_transition I see here changes in heat capacity with increasing temperature on curve on the right graph..
-
Mercury, Venus, Earth, Mars, Jupiter, Saturn. It is just 6, not 9. Learn some mathematics..
-
What happened to Coca-Cola? Is it not working anymore? ;)
-
I think you've got the wrong page, because here we see some kind of carrot grater... ps. But seriously M5 Max (release date March 2026) is newer and faster than M2 Ultra (released 2023).. “Think differently” (which I interpret as: "think like an idiot") Search for M5 and M2 on this list: (they are in 1/3 of the page) (just a few lines below M5 there is Intel for $420 and a bit below is AMD Ryzen 9 for $400)

-
Gfx for $5k is too weak. Such cards are used for bitcoin mining. ChatGPT's A100 is for $10-20k and H100 is for $30-$40k >= 30k of such A100/H100 is used simultaneously.. The best one as of 2026 from Mx line is this one: https://www.cpubenchmark.net/cpu.php?cpu=Apple+M5+Max+18+Core&id=7231 It looks poor in comparison to multi-thread charts of the best AMD and Intel. 3x slower (173k vs 58k rank) M5 only wins in single-thread charts. https://www.cpubenchmark.net/singleThread.html
-
Not really. AMD Ryzen Threadripper PRO 9995WX has 96/192. https://www.cpubenchmark.net/cpu.php?cpu=AMD+Ryzen+Threadripper+PRO+9995WX&id=6693 H100 i.e. what is used by ChatGPT has 16896 cores. A100 has 6912 cores.
-
Except that it's not a Polish doughnut. Because Polish doughnut don't have holes in them. They look like this, for example: It's hard for them to have holes when they're filled with jam or cream inside.. The jam can be rose, currant, cherry, cream chocolate, vanilla, pistachio, etc. Rose jam is the most popular. Here is the procedure for making them: https://www.instagram.com/reel/DUGgJuLCF47/ Statistics show that 45-55% of all doughnut sold are filled with rose jam.


-
Apple has created their own ARM processors.. https://en.wikipedia.org/wiki/Apple_M1 Intel and Apple never played on this play field. Microsoft's Window Server edition has 20% of web server market, and Linux has 80%. These statistics can be easily falsified, because you can run a VPS with Linux on a Windows server.. Statistics are generated by bots that access websites. A database is built based on the server's response. However, it doesn't have to be a real server, but a VPS, which can be run in Docker on both Linux and Windows (which are the actual host OSes of this dedicated server). As a result, you receive only information about a VPS and not about a real dedicated server. Notice difference between enterprise vs customer market.
-
Indeed, a great movie. An hour well spent. From what perspective should I comment on this? He made a lot of mistakes, starting with that 500ms absurd delay that started the whole investigation. Everything was overcomplicated to the point of absurdity and not tested enough in real life (hence the memory leak). Fedora holds a small share of the desktop Linux market between 1% and 4% of total Linux usage. Fedora test and rolling, a fraction of Fedora. So it didn't work out globally. So the effects of this backdoor were very limited. An attempt that failed. You won't hear about the attempts that were successful... ;)
-
He is making mutually exclusive statements?
-
Both Android and iOS are modified Linux kernels that have had a lot of functionality removed and replaced with something else. You can partially or fully reverse this. Without rooting, partially. With rooting, entirely. Since you say you have a Samsung, start by downloading Termux. I recommend the versions from F-Droid: https://f-droid.org/pl/packages/com.termux/ It does not require rooting, but rooting your phone can be a game-changing solution. Unfortunately, you might have trouble typing on a Samsung phone with a Samsung built-in keyboard, so I recommend using the Google keyboard for the first run after installation. Then use 'nano .termux/termux.properties' (notice dots) and enable line with 'enforce-char-based-input = true' nearly the end of the file. i.e. remove hash (#) After that you can go back to Samsung keyboard. Restart Termux. You should be able to work normally (just like on any Linux terminal). ps. If you have a bricked Samsung i.e. PIN & password protected, Face-ID protected, Google account protected (FRP), bootloop etc., I can help you resurrect it.. All Linux kernels older than 2021 have a critical bug that allows you to gain administrator privileges without knowing any password. Due to limitations and modifications, this particular bug does not work on Android and iOS. ..watching your video now.. The bug in XZ from 2024 had no significance. Someone introduced a backdoor to the app, but people didn't install the update globally. It was only in test and rolling versions. It didn't reach the stable versions because it was detected. The vulnerability I mentioned earlier was experienced by everyone from 2011 to 2021 (or they still have it if they can't update the system). ps2. Hacking Linux is incredibly easy if you have physical access to the machine. Much easier than hacking Windows with physical access,
-
https://en.wikipedia.org/wiki/Liar_paradox
-
ChatGPT has 400 GB of GPU memory. At least 5 nVidia cards, each with 80 GB of video memory. In practice, you need a little more because you also need KV, etc. That's where those 100 billion parameters come from (100 billion x 4 bytes for IEEE-754 32-bit float = 400 GB) Do you have access to such equipment? NVIDIA H100 (PCIe) $25,000 - $30,000 NVIDIA A100 Approximately $10,000 - $15,000 Wrong. LLM models (except for Grok, from what I've heard), have a context window. They don't know what's outside that window. They only process what's inside the context window. This is expressed in tokens. English word = 1-2 tokens. Programming 1 character = 1 token. After chatting with ChatGPT for a few hours, ask it, “What was the first question I asked you today during this session?” It will respond with something found in the middle or bottom of the entire chat window. Grok stores the session on the GPU. If the internet connection is interrupted (this is not visible, it may be due to the browser or another factor), Grok releases the GPU for other users. As a result, I cannot ask Grok any question that refer to previous ones. It does not know what we were talking about a second ago. I was using Firefox on Linux. You may have had a different experience, but from my point of view, Grok is useless. After all, these are the effects of what we discussed in another thread about the US education system in the early stages of education. When you learn selectively, you have selective knowledge on basic topics. At university, there is no time to fill in the gaps after years of mediocrity.
-
This one is real: https://www.youtube.com/@Volonaut
-
I think you're confusing autism with psychopath/sociopath.. There were cases of mental illness/disabled in this family: https://en.wikipedia.org/wiki/Nerissa_and_Katherine_Bowes-Lyon
-
In your cursory research, you missed the key word, namely, enterprise vs. consumers. Statistics indeed show that Claude (Anthropic's LLM the biggest product, which is not research model) is used more often in enterprise. But the price of its tokens can be nearly 10 times higher than the price of ChatGPT and Gemini tokens, so if its market share is expressed in dollars and not queries, it doesn't really reflect the true percentage of the amount of electricity used to generate the responses. What are these enterprise LLMs mainly used for? I think it's for programming, office support, answering customer questions on store websites, replacing human call centers and store support. It's easy to conclude that these will be marginal uses of LLMs compared to the consumer market (as there are 8 billion potential users worldwide). ChatGPT answers 2.5 billion questions daily. Claude (Anthropic) market share both enterprise and consumer markets merged: https://fatjoe.com/blog/claude-ai-stats/ If the above is not enough: Enterprise: https://www.google.com/search?q=llm+by+market+share+enterprise vs Consumer: https://www.google.com/search?q=llm+by+market+share+consumer ps. If we don't know how this market share is calculated - whether in dollars, the number of queries, or the number of tokens processed - it can significantly distort our understanding of these statistics. If something costs $10, 10 times more than the competition, then clearly in dollar-based statistics, it will have a higher percentage than those offering it for $1. And mislead us.
-
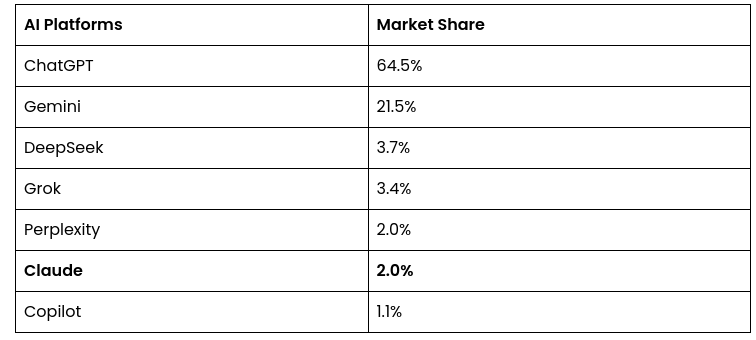
You always come up with this nonsense when you're out of arguments. So let's look at the LLM statistics. ChatGPT 64.5%, Google Gemini 21.5%. 64.5+21.5=86% of the LLM worldwide market. Grok 3%. 86+3=89%. Are you all okay? I don't understand what you wrote here. I didn't write about any hypothetical things. Datacenter = the place where these LLM questions are processed. If ChatGPT (64.5% of the world market) runs on Azure, and Microsoft claims that Azure is 100% renewable, this means that 64.5% of the world's LLM runs on renewable energy. https://datacenters.microsoft.com/globe/powering-sustainable-transformation/ Same with Google Gemini. So 86% of LLMs are on renewable energy. Repeat with smaller models.. It is physically unprofitable to have a data center without renewable energy.

-
ChatGPT does not have their own servers- they use cloud in 3rd datacenters. LLM mentioned by the OP is Google one, so it is in Google Cloud datacenters.
-
Irrelevant (and untrue as I pointed it out) to this thread were your words that LLM/datacenters has a negative impact on the climate. When each data center has its own solar panels and wind farm, their impact on the climate is zero. So please do not mislead people with your false statements.
-
Nonsense. This is an analysis of what happens to your energy from any electronic device (such as a server in a data center) after it's done these calculations. The heat from the light bulb or the heat from the server can be used at a later stage.
