Dagl1
-
Posts
365 -
Joined
-
Last visited
-
Days Won
4
Content Type
Profiles
Forums
Events
Everything posted by Dagl1
-
@CharonY Thanks for the explanation! That adds quite a few things to the way I see it. Now back to the topic at hand (as I am also partly to blame for derailing it), do you all think that if this eventually dies down, and things do not change (in the system), these types of protests and riots will become more frequent, or will this be (at this scale) more a one-off thing?
-
Maybe I misunderstood, but you are saying tribalism and racism are not quite the same and I agree, but biologically speaking, we do have different responses (increased amygdala, reduced/slower prefrontal cortex inhibition when seeing out-group people) to in-group and out-group people. This is what I would consider tribalism, but one of the easiest ways for our brains to identify in- and out-group people is physical appearance (which is where racism starts, but I suppose maybe you mean that racism goes much further than such relatively fundamental responses)? Please correct me if I am wrong or misunderstood you, I also realise that studies such things as increased amygdala response when seeing people with a different skin-colour may fall in the non-reproducible category of psychology/neuroscience.
-
Together with your other statements, this answer seems as if you are not agreeing with the other points, or have not gotten any new knowledge or insight from peoples post, this could of course be completely untrue, but at the same time, based on the tendency of your previous answers and posts on other topics, it is not unreasonable (to me) to think that you still hold your initial believes, not understanding that systemic racism exists, denying its existence, or not seeing how the fact that it is currently a bigger issue for some people than for others (and should therefore first be solved for those people (referring back to the comment about every group of people (on average) possibly being equally as racist)). Some post ago you asked people in this forum to help you comprehend; they have attempted to, did it make a difference, do you now understand more than before? If not, why? Again I could be completely misreading it, but to me it feels like you evaded the other questions I asked.
-
Maybe it is an interesting thing to research yes, but does this, together with other people's explanation and Dimreepr's video explain to you the problem people (non-white/non-christian) are facing? Your previous posts seemed to ask why these things were problems, did these questions get answered and do you understand the problems and why people are currently battling racism coming from white people that is ingrained in the system (within the USA, and possibly other places in the western world)? Do you agree that white-people disproportionately hold power in society, and do you also agree with the fact (which is a strange question) that non-whites are more often victims of police misconduct, brutality, and assault. Do you think things should be systematically changed because of these things that have been shown to you?
-
You said it more clearly than I did!
-
Because some people have been on the receiving end of racism for much longer than others, potentially making their experiences different. But the problem is that currently white people hold much more societal power than those with other skin colours and those that are parts of religions that are not Christianity. This means that even if there would be equal racism among all people, the consequences disproportionately affect non-white/non-Christian (in the western world!) people. Hence people speak of systemic racism, yes it may be (please note that I am not saying this is the case) the case that if most power in the USA and other western countries would lie in people of colour, they would be equally racist. But they are not in power (generally) and thus the current issue is that they are disproportionally discriminated against. If we ever get to a position where it is the other away around, then we have a different issue to solve.
-
What things have you thought of, what things are things are there to consider in this question? What is osmosis and how does it work?
-
Would that be a bad thing? I do myself subscribe to the idea that those in power should be held to higher standards than those that are not, and that if you do something wrong or abuse your power, you should be punished more severely (the higher you are, the longer the fall. comes to mind).
-
I think Jack means that besides being punished for murder, the fact that this person was part of the system (society), and misused his power, he is breaking the social contract, which should be punished by life in prison with no chance of parole (according to Jack). If this police officer had not killed anyone, but still abused his power, I think Jack would also want this person to go to prison for life, without parole because it is breaking the social contract that individuals sign with (are forced to sign with) society.
-
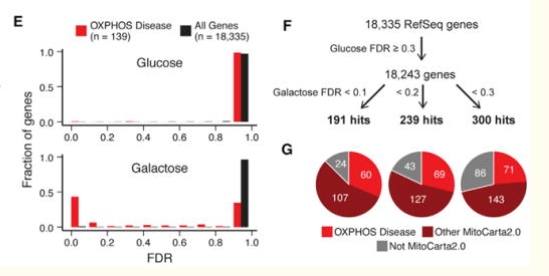
Is the paper in question pertaining the first paper, which looks at the different genes, or the paper explaining local FDR. I am not sure if the first paper actually uses FDR (they just call it FDR, but from its description I think it is local FDR (do you agree?)). Regarding the independence of its p-values, each cell line is randomly mutated through the use of some mutagen (if I remember correctly), meaning that each cell line's mutation should be independent from all others (going by the idea that the mutagen does not target one gene over another which won't be entirely true as the size of one gene may make it more or less susceptible to mutations that lead to problems (not all mutations lead to problems)). I am not comfortable enough with the statistics to say that more studies rely on the independence of P-values, but I might be able to fill in details regarding general methods, so you could come to the conclusion if that is or is not the case (aka = I can explain the biology, maybe that helps you interpret the data/study better). If we go by what you said: I don't really understand how that would work with figure 1.E, as we can see fraction of the total genes at certain FDR values. Could you elaborate? (I am not saying your explanation/interpretation isn't true, I just can't connect your explanation with that figure). Thanks for taking the time to look into it and replying! -Dagl
-
Hey everyone, At some part during my studies I had to read and subsequently discuss a paper, I remember this as one of the more difficult papers I had ever read, although after the discussion understood everything. I recently looked back at the paper and now see that I do not understand it anymore (or maybe never did). https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5474757/ My question is specifically about the false discovery rate metric used here (see text and picture at the end of this post). For context, I will briefly explain what they do in this paper before asking my question: In this paper the researchers introduced random mutations into cells (on average each cell would have a single mutation) with the aim of identifying genes involved in oxidative phosphorylation (a process that can utilise both galactose and glucose). Galactose is only used in oxidative phosphorylation, while cells can use other pathways to create energy from glucose, thus by letting mutated cells replicate a few times and then splitting them up into glucose- or galactose-containing medium, they can identify mutations that only target oxidative phosphorylation (as cells with these mutations will remain alive within the glucose-containing medium but died in the galactose-containing medium). What I am wondering about is their usage of false discovery rate, as they obtain genes 'with a given false discovery rate'; this implies to me that they are talking about local false discovery rates, in contrast to the false discovery rate of a given experiment (I know it as the rate of false discoveries versus the total amount of hypotheses tested). From what I understand (from this paper: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC520755/), local false discovery rate is the chance that a given gene is a false positive. I am however not sure if that is the case or that my mind has made up this interpretation to let it all make sense. Below is an excerpt of the original paper and the specific passages that discuss the false discovery rate. If anyone could correct me, verify that my interpretation is right, or supply general comments, that would be greatly appreciated! -Dagl Stay safe and healthy! We also observed this expected enrichment of positive controls at the gene level, and the known OXPHOS disease genes scored significantly better in galactose compared with glucose, as measured by the false discovery rate (FDR) (Figure 1E). Moreover, the fraction of OXPHOS disease genes below 10% FDR in galactose was enriched 39-fold compared with the background of all genes. We used the MAGeCK scores to define a set of genes that were specifically necessary for survival in galactose relative to glucose. We filtered out 92 genes with an FDR below 30% in glucose medium because these likely represent broadly lethal genes that cause non-specific cell death. We then identified hit genes enriched for lethality in galactose at three FDR thresholds: 191 “high confidence” hits at 10%, an additional 48 hits between 10% and 20%, and 61 hits between 20% and 30% (Figures 1F and 2).
-
Optimal primer concentration qPCR
Dagl1 replied to Fanatic_scientist's topic in Microbiology and Immunology
What qPCR kit (or just enzyme) do you use? It depends on both the primers in question (how easily do they form primer-dimers) and the enzyme used, however I generally used 250 nM (for both the forward and reverse primers). Optimal primer concentration can only really be obtained by titration, but I have only done this (once) when initial results were dubious/contained primer-dimer peaks (increasing annealing temperature wasn't really viable/did not help either). When titrating, Thermofisher (Sybr Green) recommends checking the 100-500 nM primer range, however other researchers sometimes check between 50 nM and 900 nM (as of researchgate). https://www.thermofisher.com/nl/en/home/references/protocols/nucleic-acid-amplification-and-expression-profiling/pcr-protocol/sybr-greener-qpcr-supermix-universal.html -
I suppose one way of thinking of it (which I am not able to defend with actual statistical data) is that smarter people may have a higher chance of finding an answer or new idea at any given moment, but that it is not a certainty. I am not sure if smart people will by definition come up with more ideas, but since that is a thought that pops up in your head, let's go with it: A smart person at any given moment has a higher chance than you to think of a good idea or some new knowledge, but that doesn't mean that said smart people will do so, therefore you can and probably should (if you want to create new knowledge) try, as there is always the chance that you will come up with a new idea that other people have not. The smarter people may outperform you in quantity, but there is a (almost) limitless amount of new knowledge that can be created, so just go for it, the chance that a smarter person will come up with THAT particular piece of new knowledge before you do is not hundred percent, so if you try enough, you may/will come up with new knowledge. Potentially many times someone smarter will have thought of it before you, so you try again, and again, each time rolling the dice and eventually you can win the jackpot (so to say). That said, I don't think being smart alone is a good determinant for creating knowledge either. Someone has to be interested in something, has to be thinking about the right stuff, at the right time, and combining already existing pieces of knowledge in just the right way to create a new piece of knowledge.T here seems to be some amount of 'randomness' to be involved in that process. People also have to be interested enough to write down and publicize there ideas for it to be a real addition to the common pool of knowledge. Additionally, a smart person may focus too much on a single subject to never come along a new piece of information, so by being interested and reading about many things, you increase the chance of coming up with something new anyway. You said you have a craving for knowledge, so if the above doesn't resonate with you, just go forget creating new knowledge for the sake of creating new knowledge. Instead, pursue finding/inventing new knowledge for the sake of bettering your own understanding of any given subject: in your pursuit of new knowledge, you will gain existing knowledge and new insights (that maybe other people have already had, but for you they will be new knowledge), and remember that every new piece of knowledge (in your mind) does bring you closer to the possible discovery of something truly new, unseen or unthought before. I found the book 'Where good ideas come from' by Steven Johnson, an interesting read about how new knowledge is (generally) created. I don't know how true the book is, but I feel it may be a perspective that can help you remove doubt from oneself (it is not about doubt in the slightest, but about the ideas that new knowledge generally only becomes available when several 'facts' or concepts known today, come together in someone's mind. That mind does not have to be a genius). I hope this helps, and if it does not, then I hope someone else can maybe provide you with something to reduce/eliminate your self doubt. PS. You can always go the Mohammed Ali route and just keep saying that YOU ARE THE GREATEST and that by definition YOU WILL CREATE NEW KNOWLEDGE (I do wonder about the efficacy of this method though).
-
How would you verify the localisation after you get some data? Anyway I hope this helps you on your way with your essay, I am signing off for now.
-
Sure! So we have a protein that is uncharacterized, meaning there probably are not going to be antibodies available. We can try producing proteins against it, but we could also try something else. What is cloning and what ability does it give us? How could we fuse these two things (fluorescence and cloning) together? The answer has a caveat though; there is of course a potential drawback to using fluorescence, in that it may not accurately describe localisation due to how we use fluorescence, but this is something that can be discussed/worked around later, and may not be in the scope of the question.
-
What are ways that we can find out the localisation of a protein? How do we employ this by using cloning?
-
Microbiome transfer from another species?
Dagl1 replied to Hans de Vries's topic in Microbiology and Immunology
Thanks for the links! -
Microbiome transfer from another species?
Dagl1 replied to Hans de Vries's topic in Microbiology and Immunology
I don 't know such reports, could you link some studies that show this? To your other question, a bit difficult to say since its pretty much unknown territory, I would imagine however that such transplants would make people quite sick due to unfamiliar bacteria, that normally don't live in the human gut micriobime, being added to that environment. I doubt people will suddenly become like tigers ^^. -
I don't know of any such studies. I also don't know if psychopathy actually increases chances to get offspring. Additionally there is no reason to think that psychopathy is something caused by specific genes, only that certain genes increase the risk (as of now, without enough evidence to support causal links, almost everyone has a chance to be(come) a psychopath, but certain gene variations can increase that chance). I don't see how 'brain drugs' are related to social engineering of non-psychopathic people (is it different for psychopathic people?). To your last question, no I haven't heard of such studies.
-
I don't think evolution, especially for animals such as humans, where each generation takes quite a while, and which have extremely high inter-tribal (national) relations, will suddenly have more psychopaths in the genetic sense in the next hundred years. Is there any reason to think psychopathy is determined three or only a a few gene variations? About the fitness of a polygenetic trait that only increases fitness when all the right variants are in place: If they are not carried on the same chromosome, there inheritance is going to be a lot more difficult. I don't know about a way to simulate such a specific example. Also there are too many confounding variables to give a clear picture and to answer your other questions, at least for me.
-
Per ml? or microliter? If you mean ml... then I think this is too low. In case you are talking about microliters, then 5nm/ul is still really low. You could attempt precipitation, but it also depends on the volume you have this amount in. I would always attempt using the same amount of RNA, so you may want to dilute the 80ng to 50ng in a reaction, and then using 50 ng of the 5ng/ul by taking a lot of volume (10 microl of RNA in your reaction). I am not entirely sure if that will be high enough for all subsequent procedures, but I think it could work. It is pretty low though, but I think it is worth trying, especially if you cannot get any new RNA from brain tissue. Maybe Charon can verify whether or not this really is the case.
-
I am not sure about the relevance of the the HSA-miR palindrome, but my biochemistry knowledge is also not very up to date regarding how endonucleases cut exactly, maybe Charon can elaborate
-
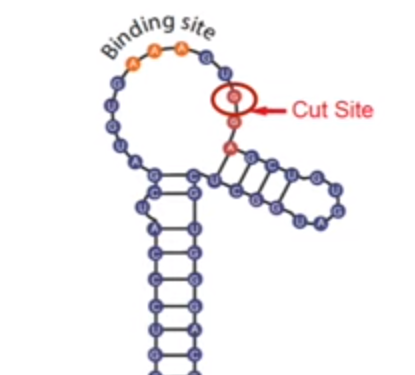
I think I may be misunderstanding, so apologies if I am missing the mark, but: in humans, each TSEN enzyme/subunit cuts one strand, and they don't seem to be directly complementary of each other. Also, a lot of mRNA is 'double-stranded' or forms hairpins/secondary structures, non coding RNA even more (I think). Important to note that mRNA normally binds to many mRNA-binding proteins, and therefore predicted structures (minimum free energy calculations) will often not actually form inside the cell (or be different from the predictions). The 5'UTR (Untranslated region) and 3'UTR of mRNA contains many structures as well. About 190 human genes (I think) contain an internal ribosomal entry site (IRES) within their 5'UTR, which can modulate ribosomal activity, these generally have the shape of hairpins as well. A viral enzyme of herpes virus, SOX, cuts at a single point, but recognises specific sequences in hairpins, so both structure and sequence is important. I don't really understand what you mean? https://journals.plos.org/plosbiology/article?id=10.1371/journal.pbio.1000307 https://journals.plos.org/ploscompbiol/article/figure?id=10.1371/journal.pcbi.1003517.g004 https://en.wikipedia.org/wiki/Insulin-like_growth_factor_II_IRES (couldn't find an article with eukaryotic IRES that shows it nicely)
-
Imagine animals, such as apes, that live in tribes. Do we count a single tribe as a given population, or do we count all tribes as a given population. If we are talking about all tribes, then their size, frequency of inter-tribal breeding, and the amount of survival advantage provided by the trait, will determine the speed. Of course also the initial size of the given population is important. Simulations can sometimes account for these things, but it's quite a lot of work to tweak all such variables to mimic reality (I think). If you just want a broad idea, online simulators should be okay. I remember using toy models/simulations at university, but those were made in-house. You can play around with some simulation programs (important to run many simulations, as the outcome of each will be different): http://popgensimulator.pitt.edu/graphs/allele#! Or look for some other other gene frequency simulations. Maybe other people have more concrete answers (not sure if that simulator can do what you want).
-
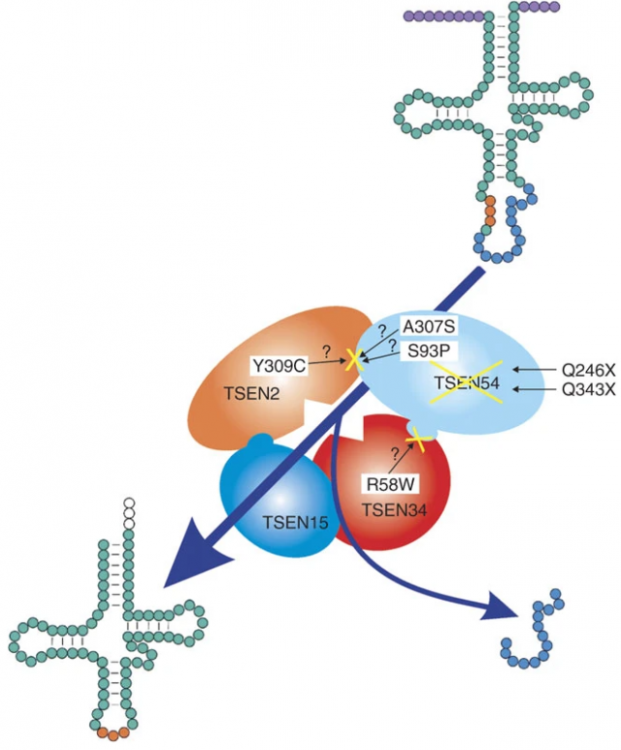
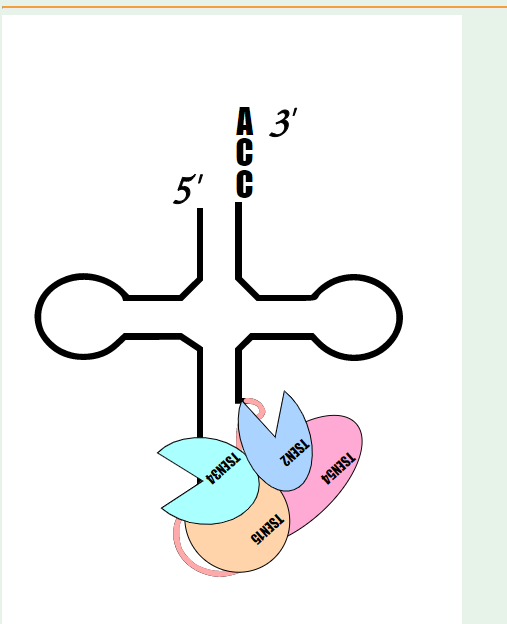
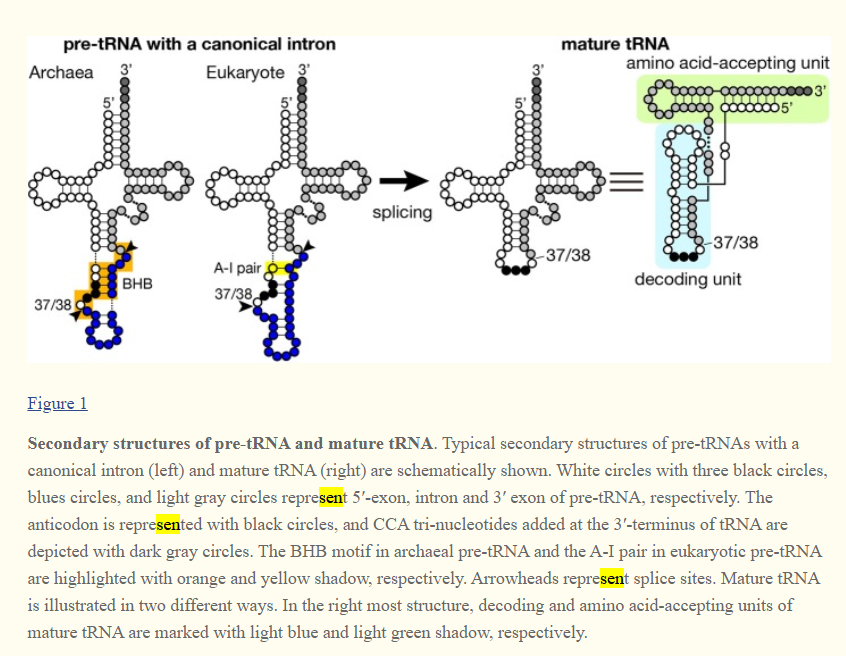
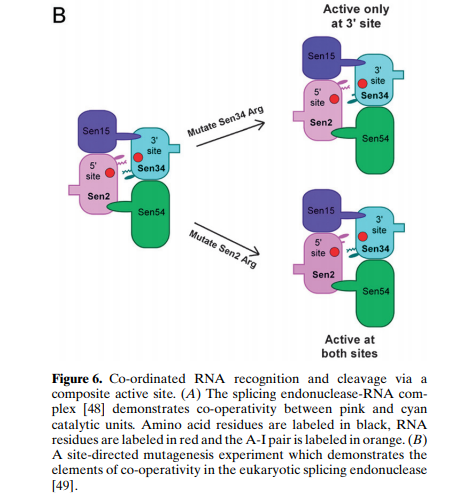
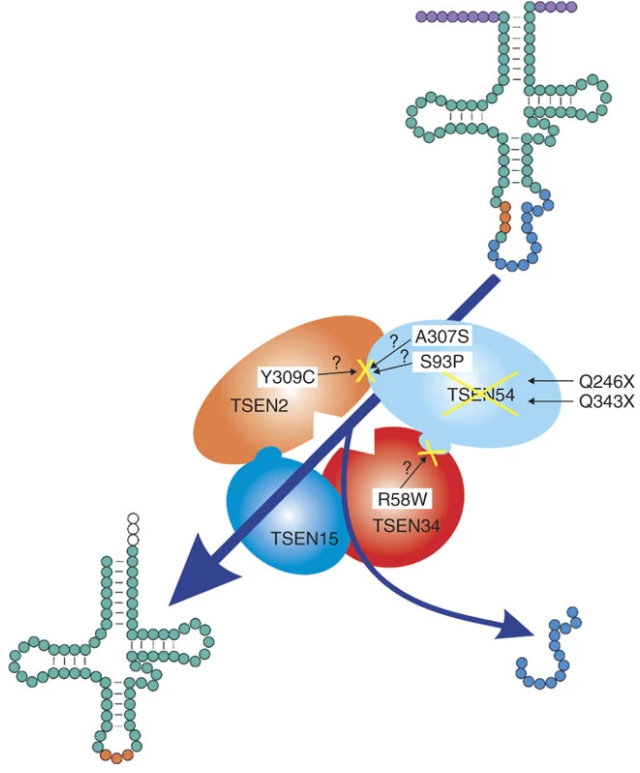
I may have to brush my knowledge about tRNA splicing, but could you elaborate what you mean by : I have been trying to find if SEN (TSEN in humans) tRNA splicing endonucleases actually cuts the opposite strand, but so far I have not found that they do: It definitely doesn't seem palindromic though. From quickly scanning these few articles it seems that for tRNA splicing there are two catalytic (TSEN2, TSEN34) subunits and two structural (TSEN15, TSEN 34). The last article (sci-hub link) shows this through mutating SEN (non-human version) 2 and 34 (see last picture). Please note that I have included the first article because it shows the structure of the complex quite nicely (I think), but that article is about specific mutations that cause pontocerebellar hypoplasia. Hope this is of interest/relevant to you! Articles (hopefully in order of the pictures): https://www.nature.com/articles/ng.204? http://www.genesilico.pl/rnapathwaysdb/Pathway/step/72/ https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4090602/ sci-hub.tw/10.1007/s00018-008-7393-y