


timo
-
Posts
3451 -
Joined
-
Last visited
-
Days Won
2
Content Type
Profiles
Forums
Events
Everything posted by timo
-
C++ supports state-of-the-art random number generation. So it would be easiest to use a c++ compiler for the code (I expect that it should compile the C parts just fine) and pick an rng that is provided by the language standard library. So: Pick up to one: http://www.cplusplus.com/reference/random/ . I do not expect that the choice of the rng matters for this case. But it is a good habit to never run a Monte-Carlo simulation without a good rng, and including one is really easy in most programming languages.
-
Do I understand it correctly that the issue you see is the following: One unit in x-direction is a different amount of pixels (or cm on paper, if you'd print it out) than one unit in y-direction. Is that what you mean? That is indeed the case. I have never considered a problem. In my experience, this is the default behavior of most plotting engines. It is normal that in addition to looking at the shape of curves you also have to look at the numbers on the axes (small effects can often look large if you just zoom-in into the graph). And I do think there are more use-cases for having different spacings in x- and y-direction than for having the same spacing. In fact, it is very common that x- and y-values are not even comparable (e.g. one can be a time and one can be a number of people). If you really want to have identical spacings, I think you can at least approximate that by setting the ranges by hand and forcing the aspect ratio or the size of the picture to fit to the ranges (same height and width of the x- and y-ranges are the same, double width if the x-range is double the y-range, etc). To set the range by hand, you can use curve(x^3, -3, 3, ylim=c(-3,3)); grid() Not sure how to set the window size by commands, but it should be possible. For an approximate solution, if you use R-Studio (which I really like for working with R) you can just resize the plot window to have the aspect ration you want and then export the image.
-
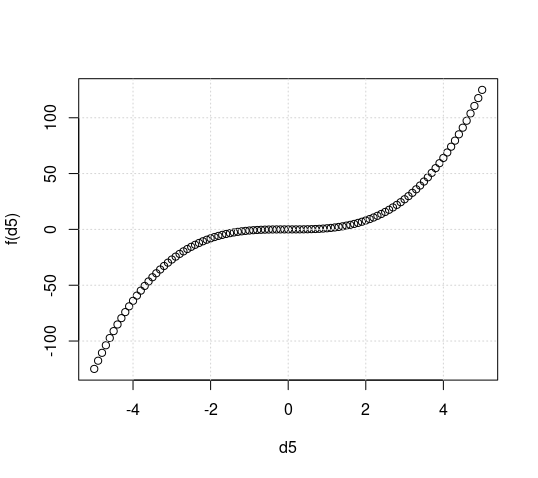
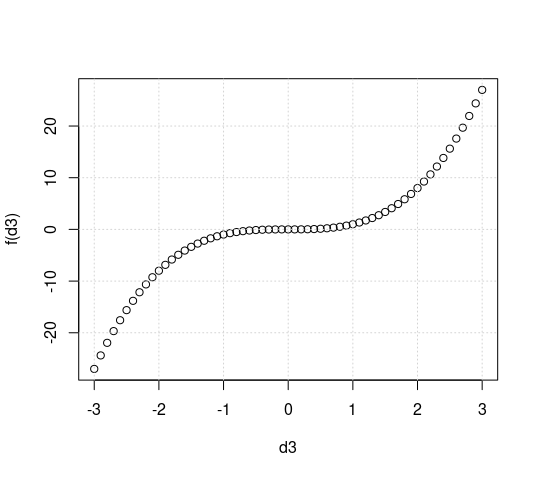
I kind of did what in hindsight I feel should have been provided by you in your starting post: Created the plots you spoke about and posted them here. The code is f = function(x) x*x*x d3 = seq(-3, 3, 0.1) d5 = seq(-5, 5, 0.1) dx = seq(-3, 5, 0.1) plot(d3, f(d3)) grid() plot(d5, f(d5)) grid() plot(dx, f(dx)) grid() The created plots are attached. I see no problem with them. I am not aware of any technical problems that R has. While not the question: I do not recommend to get used to R just because it has the reputation of being the most common software used in statistical data analysis. The statement may actually be true. And R is not bad, either. But I feel that Python can already compete with R in terms of (advanced) functionality, and will be the future. And for just plotting functions, there should be much easier solutions / more comfortable solutions (I had used gnuplot with lots of success for a long time).

-
Is gravitation exists?
timo replied to Azerbaijan land of fire's topic in Modern and Theoretical Physics
That news came as such a shock to me that I dropped my coffee cup. Okay, seriously: You probably heard that in some context of "... is in reality just curvature of a four-dimensional space-time" (or even more weird context - my example quote at least makes sense on the mathematical level). A guy named Albert Einstein revolutionized our understanding of gravity some 100 years ago - from an understanding that can be taught to every school kid to an understanding that is taught as an elective specialization course for university students of physics. I imagine there are a lot of ways to make strange-sounding claims coming from that. But I think it is safe to say that it can be demonstrated that gravity exists. Edit: too late and even with the same joke ... 🙄 -
How long before a COVID-positive person can no longer transmit the virus
timo replied to Alfred001's topic in Medical Science
Quarantine recommendations are 14 days. And I think this is exactly for this reason: The general time-scale that an infected person is infectious is 14 days (not taking into account re-infections which are still an open question). At the beginning of the Corona situation I did some simple simulations for the development. Apparently, I used 12 days back then, but I do not recall where I got the number from. -
Environment and preventing the next global pandemic
timo replied to Buckeye's topic in Ecology and the Environment
I am aware that this is not the point of the thread, so sorry for nitpicking on this. But since CharonY's point B) was my initial reaction when I saw this thread, I'd like comment on this: Saying that "Corona virus disease first emerged in Hubei province China in Dec 2019" is much less specific than the "current global pandemic caused by Sars-cov-2 got it's start about the middle of last November when patient zero contracted an infection from a wet market in Wuhan province when he purchased a pangolin from a wet market which he had for dinner". Specifically, "first emerged" can be read as "was first discovered", which is actually very different from "was first transmitted to a human" (i.e. patient zero). That sounds like it could be correct to me. Your story sounds like an American president could have made it up while straying away from an unrelated question asked by a reporter. I cared much for the origins of Covid-19, so I am not even an interested layman on that topic. But the very first Google hit I get on "origin of Covid-19" is a relatively recent report about a WHO spokesperson saying that Wuhan may not even be the location of patient zero (let alone a pangolin sold at a seafood market): https://www.foreigner.fi/articulo/coronavirus/who-admits-wuhan-may-not-be-the-origin-of-covid-19/20200803155142007196.html @Buckeye.: I am aware this post may appear a bit rude. That is not my intention, and no offense intended! I just feel you should question if what you think you know is really correct, and I don't know enough about the topic myself to do that in a more constructive way. -
It isn't. Car traffic makes up ~10% of the world's energy-related emissions (https://www.fia.com/sites/default/files/global_reduction_in_co2_emissions_from_cars-_a_consumers_perspective_0.pdf [*]), and that's not even considering construction, agriculture, forest fires, melting of permafrost ground, methane-release from the sea, etc. Assuming the thread is not about how realistic the consumption values are: I did not follow the link, but there are two (related) ways to solve such questions: 1) First try to find out how much the consumption would be per single km. Then, from that number find out the consumption per 100 km (hint: it's 100 times the number before). 2) If you know how to solve equations, solve "88 l / 100100100 km = x / 100 km" for x. I strongly advise to try solving it in the form I wrote down, i.e. including the units, not as "88/100100100 = x/100". Especially since the thread title is "Dimensional Analysis". [*]: I am totally aware that this is a car lobby publication and that their choice of world-wide values has probably been to downplay the share in the major car markets. But I have no reason to doubt the approximate value.
-
Wood-burning as an alternative to fossil fuels
timo replied to ScienceNostalgia101's topic in Chemistry
Not sure what the focus of this thread is (and the two replies so far certainly don't help me to identify a focus). So I'll just throw in a few random comments: - You do explicitly mention "hiring recently-unemployed people". I am not sure how different that is to "hiring people" to you. For hiring people to do X, there are the obvious questions who hires/pays and often also how X competes to other things that could be done with the (monetary) resources. I think there is no shortage of good ideas that someone could do if they were just given the resources. Restricting your hiring to recently-unemployed people would be considered inefficient from a free-market perspective (note: I explicitly do not mean that the free market perspective is the one you need to take - but it is a major voice in economic decisions in most countries). Maybe it is more efficient to re-assign a trained lumberjack and have the unemployed history teacher help in a children daycare, for example. - If you do not re-grow the trees, burning wood is not much different from burning fossils fuels with respect to the climate impact. It is the re-growing that makes wood count as a renewable energy source. (Of course, burning the wood to replace some fossils is better than just burning the wood in forest fires - greetings to Brazil ...). - To burn wood instead of fossil fuels you have to change the energy-generating technology, for example replace oil burners with wood burners for heating houses. This is not a problem in principle. But you need to make sure in practice that this pays off. I would actually not be too surprised if the current wood market in the US could simply absorb some extra wood you cut, and that you would not need to "make room" in the fossil energy sector. - For educational purposes, I strongly suggest you try to do some estimate calculations about how much fossil fuel usage you could reduce by having extra wood. In my experience, most people do not understand how extreme a replacement of fossil fuels is in terms of scale / the numbers. The US national oil consumption should be easy to find, a kg of wood has roughly the same energy content as a kg of oil => just have a look at how much of an impact that replacement would have. Spoiler: I am not aware of any future energy scenario that assumes that we can simply replace fossils with wood and forget about all these annoying issues with solar and wind. -
How to execute the function to fill the list and to print it
timo replied to zak100's topic in Computer Science
I meant the function in the sense of a mathematical function in this case. The point is just to highlight that you have five different functions. The code of the functions would be: def fun1(e): return e+0 , def fun1(e): return e+1 , etc. Except that the functions are not named fun1 -
How to execute the function to fill the list and to print it
timo replied to zak100's topic in Computer Science
You are not invoking the function fun1(e) and storing the results in the list. You are storing five different functions fun1(e) in a list and never invoke them. Namely, the functions you store are fun1(e)=e+0, fun1(e)=e+1, fun1(e)=e+2, fun1(e)=e+3 and fun1(e)=e+4. What the print tells you is exactly this: Your list contains five functions named fun1 at the memory locations 0x7f6d8a364e18, 0x7f6d8a28a158 etc. If you wanted to invoke the function and store its values you'd need to invoke the function and type something like fun_list1.append(fun1(42)) (in this case you invoke it with the parameter 42 - every other number would work, too). And of course writing fun_list1.append(42 + j) would be the cleaner code to do the same without the unnecessary function. There are legitimate reasons why sometimes you want to store an actual function instead of the function result (you don't know the argument at the moment, you want to execute it multiple times, ....). You can call the stored function fun1(e) just like any other function. If you want to see evaluated results, change your print statement to print(x(42)) and your output should become 42, 43, 44, 45, 46 (again, the argument 42 is just a random number, and any other number should work). -
a) The variable is a map (in Python language: a dictionary or dict). Maps are pairs of unique keys and possibly non-unique values. Typical cases are lists of usernames (as keys) and the users' passwords (as values for the keys). In your case it is a map of string keys that each have an integer value. b) The curly brackets are a way to define dicts in Python. You should be able to literally type in a dict like "{'a':0, 'b':1, 'c':2}". Here, the case is just a bit more complicated because the term is { <elements are generated by a for-loop> }. c) The colon separates key and value in a dict, as in my example from case b). The loop generates key:value pairs a:i for all i in range. d) The statements are the a:i. The loop runs from 0 to len(a)-1. In this case from 0 to 5. e) As mentioned before, keys in a map are unique. So there can only be at most one value for the key 'a'. The usual behavior for maps and dicts is that setting d[key] = value will either create a key with the given value in d. Or, if the key already exists, it will keep the key and set the value to the new one given. In that context, it is at least the behavior I would expect from the loop: At i=0, it sets ind['a']=0. And then at i=4 it overrides the existing value with ind['a'] = 4.
-
In mathematical terms, Omega is the same to-be-determined variable as in Example 2. In terms of Physics, it is the https://en.wikipedia.org/wiki/Angular_frequency. Example solution for Example 3: If I take x = x0 cos (wt) + v0/w sin (wt) and plug in x(t=0) = 0, then I get the condition x0 cos (0) + v0/w sin(0) = 0. Hence, x0 = 0. The first derivative of the function is dx/dt = w x0 (-sin(wt)) + v0 cos (wt). Plugging in the constraint dx/dt (x=0) = 1 yields w x0 (-sin(0)) + v0 cos (0) = 1. Hence, v0 = 1. The 2nd derivative of the function is d^2 x/dt^2 = -w^2 x0 cos(wt) - w v0 sin(wt). That one is a bit tricky, but by comparison you will see that this is -w^2 * (original function). So this satisfies the condition d^2 x/dt^2 = -x if w^2 = 1. I don't know why w=-1 is not considered here; maybe I missed something. Hope that helps. If so, it would be nice to hear what the actual step was that you got stuck on.
-
Why if at all would solar energy be expensive?
timo replied to ScienceNostalgia101's topic in Engineering
I am not sure to what extent that is common knowledge: Using reflectors to focus on a point, generate steam and then run a turbine just as in fuel-based power plants is actually done. It's called Solar-Thermal Power (see e.g. https://www.eia.gov/energyexplained/solar/solar-thermal-power-plants.php) or Concentrated Solar Power. As far as I know, for electricity generation this method is more expensive than using Photovoltaic systems, and therefore often not considered. And for generating heat you usually do not reflect+focus but simply absorb (-> Solar Collector). The biggest advantage of Solar-Thermal over Photovoltaics is that Solar-Thermal power plants can store the thermal energy to some extent before using it, so they are somewhat controllable in their generation and can generate electricity at night. In some situations, this can make them the preferred choice (according to a former colleague of mine who did a lot of energy system design for northern Africa). For the system cost I would assume that on the side of steam system, turbine and electrical system it's pretty much the same as for any other coal, gas or nuclear power plant, except that those tend to be larger and therefore perhaps more cost efficient. The difference in cost hence is heater vs. collectors+storage. I have no intuitive feeling for it, except that I expect the hater to be relatively cheap (specifically: a simpler piece of technology than a turbine). From an old Irena publication (https://www.irena.org/documentdownloads/publications/re_technologies_cost_analysis-csp.pdf) it seems that collectors+storage make up roughly 50% of the project cost (Figure 4.2 - there's also lot's of tables with more details if you are interested in those). So my answer to "how expensive can it be" would be "roughly twice the cost of a coal power plant" in terms of construction cost. You obviously don't pay for fuel (coal). End-costs for generated electricity (levelized cost of electricity or LCOE) always depend a lot on local situations and calculation method. On the Wikipedia page https://en.wikipedia.org/wiki/Cost_of_electricity_by_source the listed figures suggest 6.1 ct/kWh for Australian Solar Thermal generation and anything from 3.3 - 15.2 ct/kWh for coal. On a final note: You seem to implicitly assume that main investments into new power infrastructure goes into coal and nuclear power plants. That is not the case. Globally, new installations in renewable technologies have overtaken the non-renewables a few years ago. Even in the US, the only country that left the Paris Climate Agreement, new power installations are either renewable or gas (mostly because energy infrastructure is built private companies, not the federal government): https://www.eia.gov/todayinenergy/detail.php?id=42495 . -
A rotating vector field without a zero point?
timo replied to ScienceNostalgia101's topic in Analysis and Calculus
I'll try to express what I understood in mathematical terms. From the title of your thread I was assuming a rotating vector field would be f(x, y, z, t) = (sin(t), cos(t), 0). That is a homogeneous field that rotates around the z-axis. But your first sentence seems to be considering a time-static, rotationally-symmetric field like f(x, y, z) = (y, -x, 0), instead. I do not understand why f(0, 0, 0) had to be (0, 0, 0) in that case (even though it is in my example). Mathematically, the function could have any value. Physically, the magnetic force around a wire would be a counter-example, since it "rotates around the wire" and diverges at the origin (i.e. is undefined). Without looking it up I'd expect that the velocities of circular planetary orbits also diverge at the origin. So I think there are some implicit assumptions you make in your first sentence that you are omitting, e.g. something like "the function is continuous and defined everywhere". Your moving example would probably be something like f(x,y,z,t) = (y-t, -x, 0), I think. So now, time is back in the picture, which is a significant difference. You can quickly solve that for (0, 0, 0) == (y-t, -x, 0) and see that for all (x=0, y=t, z=arbitrary) f(x, y, z, t) = (0, 0, 0). So in that particular example, the answer would be "at each time, there are points at which the function is zero" and "there is no point at which the function is zero at all times". If you constrain the domain of the function, the first statement can become invalid, of course (if the calculated points are outside of the domain). Not sure I really understood what you were asking. But I hope this helps. -
Since no one brought up the mainstream answer to that question, yet: Consider the journals that the sources you are citing were published in.
-
I wonder how different that is from money. Effectively, you seem to get one credit for a task that you can use for someone doing another task for you (providing breakfast). There are a few differences to our current implementation of a monetary system: I assume you image a single world-wide credit currency, you seem to assume there are no fractions of credits, I am not quite sure how tasks/missions are assigned, ... . But most of these differences seem to be disadvantageous compared to our current system.
-
As Swansont mentioned, Hydrogen from Electrolysis (*) is mostly a storage option for electric energy, either directly or as a precursor step of synthesizing other storage gases/liquids. It has low efficiency but high energy density and low storage costs. Hydrogen is central in future renewable energy systems as the basis of long-term energy storage for the electric system, replacement CO2-neutral fuel for ships and planes, and possibly even for land-based vehicles (batteries and overhead-lines being competing technologies, there). The main drivers that can trigger its breakthrough would be cost reduction or an outright ban of competing technologies (=fossil fuels). Costs for renewable electric power generation (i.e. the "raw material") have come down significantly in the last two decades (Electrolysis from fossil fuels is pointless of course - you could just keep your fuel in the first place). Bottom line: Drivers are the need to replace fossil fuels and the cost reduction in renewable electric power generation. This is nothing new to the scientists or the energy community, and Hydrogen is not the only topic you can get excited about (-> battery technology, low-temperature heating grids, off-shore wind turbines, demand-side management, ...). Hydrogen specifically came into the news recently when the German government released its national Hydrogen strategy (https://www.bmbf.de/files/bmwi_Nationale Wasserstoffstrategie_Eng_s01.pdf). No such strategies exist for any of the other topics I mentioned. Releases like this have a significant impact on the science community and what they talk about, since everyone want to jump on the funding train. Apparently, similar strategy ideas may exist on the EU level (https://www.euractiv.com/section/energy/news/leaked-europes-draft-hydrogen-strategy/). And perhaps that's not even completely coincidental, given that Germany just took over the EU presidency. So to Swansont's question about who is shouting about a Hydrogen economy: The answer could be "the Europeans". (*) Fun fact I learned only recently: Electrolysis is not how Hydrogen is being produced on scale today. Instead, we start with oil, extract the Hydrogen and release the CO2 to the atmosphere . Totally pointless in the context of replacing fossil fuels with CO2-neutral fuels, of course.
-
A matrix M can be a function that "transforms" points into new ones in the sense of y = M*x, where x is the vector to the original point, y the vector to the point x gets transformed to, * the multiplication of matrix and vector, and M the transformation matrix. Given enough pairs of original points and transformed points, it is possible to reconstruct the transformation matrix. Please note the x and y in this case are not what they were in your post: Here, they are two vectors, while your term "x and y graph" suggests you refer to the x- and y-coordinates. If you have a single point (x,y) or a set of points (x1, y1), (x2, y2), ... then it is not clear what "transforming these points into a matrix" means. In other words: There is no such thing as transforming points into a matrix. Bottom line: It is possible to reconstruct a transformation matrix when enough pairs or original and transformed vectors are given. At minimum, for an N-by-N square matrix at least N pairs of N-dimensional vectors must be given (it does not guarantee success and will fail e.g. if two pairs are identical). The reconstruction is done by solving systems of N equations with N unknowns for N times. [And if I had the time right now I would add the explicit equations for the 2D case - that should be pretty straightforward].
-
In my experience, the concerns about climate change are the impact on human civilization over the next few hundred years. Not the impact on biological systems over thousands/millions of years. The whole climate change concern issue is a selfish, short-sighted thing of the humies, completely disregarding how great it could be for dinosaurs and turtles in the long run.
-
Here's some relatively recent ideas about a climate-friendly energy sector: http://energywatchgroup.org/wp-content/uploads/EWG_LUT_100RE_All_Sectors_Global_Report_2019.pdf Spoiler: Just as every group working in the field have said for years (I personally know roughly ten research groups in Germany alone), the authors claim that the major sources of energy should to be wind and solar. The nice feature of this paper is the global scope.
-
I am not sure I understand the question. I am not even sure that the premise is true (did Alchemy and Chemistry even exist at the same time?). But as a hint to what I guess may be the answer you are looking for: Do you understand why turning lead into gold is not within the scope of Chemistry?
-
An operator f(...) is linear if f(A+B) = f(A) + f(B) and f(a*A) = a*f(A), with addition and multiplication being the addition of two vectors and their multiplication with a real number, respectively, in your case. Alternate form of the same statements for a matrix M, vectors x, y, and a scalar a: M(x+y) = Mx + My, M(a*x) = a*(Mx). When interpreted as an operator V -> V, matrices are always linear. But it should be straightforward to explicitly show that for your given matrix by starting from one side of the two defining equations and rearranging until you get the other side.
-
Yes - if the height of people is a normal distribution or at least well-approximated by it (not sure to what extent it is). Very specifically, if you assume a Gaussian with 1.70 m as mean height, and 0.15 as the standard deviation then the chance that a person is 1.90 m or larger (in the region [1.9; infinity)) is roughly 10 %: https://www.wolframalpha.com/input/?i=integrate+1%2F((2+pi)^(1%2F2)+0.15)+e^(-((x+-+1.7)%2F0.15)^2%2F2)+from+1.9+to+infinity (note that I put explicit numbers here - if you replace 1.9 with x you'll see the erf() again in the expression for the solution).
-
Ctrl-Z just cost me a long post that I put a lot of time in and will absolutely not type in again just to be fooled by my muscle memory. Key points: 1) Consider erf() just as the number-crunching function that computers provide you to calculate integrals over Gaussians. Not much more. The explicit relation between Gaussians and erf() is https://www.wolframalpha.com/input/?i=integrate+1%2F((2+pi)^(1%2F2)+sigma)+e^(-(x%2Fsigma)^2%2F2)+from+A+to+B 2) Here's some Python code to play around if you want. It plots a) A single random variable "number of bugs a programmer fixes each day" b) The resulting "number of bugs fixed per programmer per year", which is a sum of 200 random variables in a) and itself a random variable. Key observation: The distribution looks very different and very Gaussian. c) The probability to "fix at most N bugs per year" which is the same as "fix 0 to N bugs per year" which is the same as "the sum of probabilities to fix 0 ... N bugs per year" which indeed is pretty much the same as the integral over [0; N]. The resulting curve, as a function of N, looks ... *surprise* ... like the error function. import numpy as np import seaborn as sns import matplotlib.pyplot as plt # We visualize the distributions by drawing a large sample of random variables. SAMPLE_SIZE = 10000 def randomFixesPerDay(): # Number of bug fixes per day is a random variable that becomes 0, 1 or 2. return np.random.randint(3) def randomFixesPerYear(): # Number of bug fixes per year is a random variable that is the sum of # 200 (=workddays) random variables (the bugfixes each day) return np.random.randint(3, size=200).sum() # Experimental probability for # bug fixes per day dailyDistribution = [randomFixesPerDay() for i in range(SAMPLE_SIZE)] sns.distplot(dailyDistribution, kde=False, norm_hist=True, bins=[0, 1, 2, 3]) plt.title('Probabiliy of Bug-fixes per Day: 1/3') plt.xlabel('# Bugs') plt.ylabel('Probability') plt.show() # Experimental probability for # bug fixes per year annualDistribution = [randomFixesPerYear() for i in range(SAMPLE_SIZE)] sns.distplot(annualDistribution, kde=False, norm_hist=True, bins=np.arange(150, 250)) plt.title('Probabiliy of Bug-fixes per Year\n(note smaller value on y-axis)') plt.xlabel('# Bugs') plt.ylabel('Probability') plt.show() # Integral [0; x] over annualDistribution looks like error function xValues = np.arange(150, 250) yValues = [len( [value for value in annualDistribution if value <= x])/SAMPLE_SIZE for x in xValues ] plt.plot(xValues, yValues) plt.title('Integral: Probability of fixing [0; N] bugs per year\n(i.e. "not more than N")') plt.xlabel('x') plt.ylabel('Probability') plt.show()
-
There is only one context in which I ever encountered the error function, and it the same context as here: It is the integral over the (normalized) Gaussian function. The Gaussian, on the other hand, is the most important function in statistics. The reason is the Central Limit Theorem: If you take a variable that is distributed according to some probability distribution, and then take the sum of many of these variables, the probability distribution of the sum becomes increasingly more similar to the Gaussian with an increasing number of numbers added (and the mean value of the sum is the sum of the individual means and the variance of the Gaussian is the sum of the addends' variances). The random walk is a process in which a walker takes a number of independent steps with random length and distance. By the central limit theorem, the resulting total deviation from the original location (the sum of steps) will look like a Gaussian, soon. This Gaussian gives the probability density to find the walker at a certain location. To find the probability to find the walker in a certain region, you sum up the individual probabilities of all locations in this region (i.e. you integrate over this region). When computing this integral, the solution can be expressed in terms of erf(). EDIT: I'm still posting this despite just having received a pop-up saying "someone else posted probably the same thing" 😜