Enthalpy
-
Posts
3887 -
Joined
-
Last visited
-
Days Won
1
Content Type
Profiles
Forums
Events
Everything posted by Enthalpy
-
As I imagined it, the speed would act as a v/c term known prior to Relativity, and a v2/c2 term which is a relativistic correction at a few km/s. Doesn't this quadratic term cancel out the effect of gravitation, as the satellite is in free fall?
-
Why do people need fast/strong computers
Enthalpy replied to silverghoul1's topic in Computer Science
Gpu do bring processing power but usual quad-core Cpu catch up slowly, and the Knights Landing offers the same floating-point capability. Gpu have very serious drawbacks: - They are difficult to program! If processing signal, the functions exist already, fine - but if you program anything exotic you've lost. - Their caches are tiny and difficult to use. - Many don't offer a generic instruction set. - Most are very slow on double precision. - They access the main Dram slowly. - They don't fit multitask parallelism, but many applications are parallel through multitasking. Consequently, the Knights Landing fits far better the needs of many users. Running the same instruction set as the Core is a further advantage, and if it can run the existing Os, even better. ---------- In two separate messages I told - What I need: a single Core without Avx nor Sse that executes more instructions per second; - What the Knights Landing can bring to other users. Instead of L1, L2, L3, which are quite difficult to use properly, and rarely feed the Cpu enough, a good Dram would be better. As I suggested, this needs to spread the cores among separate smaller Drams, needing to redesign the processors and also the applications. -
Why do people need fast/strong computers
Enthalpy replied to silverghoul1's topic in Computer Science
[something went wrong. This message can be removed.] -
Hello everybody! Read recently in the semi-scientific press that two Galileo satellites that were put on a wrong orbit hence are declared unusable for the European positioning constellation (GPS competitor) are to be used as a test for Relativity by observing how the onboard clocks run over the elliptic orbit. Nice, fine. Though, I'm not easy with the claim and explanation by the Press paper I read. The Press paper tells that the onboard's clock, as observed from Earth's surface, changes its pace depending on the altitude, and this will be observed. As opposed, I had imagined that both the satellite's speed (its kinetic energy) and its altitude (its potential energy) influence the clock pace observed from Earth's surface, and even, that only matters the sum of both energies, telling that we should observe no change of the clock pace, which would be the test for GR. Your opinion please? Thank you!
-
Why do people need fast/strong computers
Enthalpy replied to silverghoul1's topic in Computer Science
Intel's Knights Landing is the new thing for supercomputing. One socket carries 1152 multipliers-accumulators on 64b floats working at 1.3GHz to crunch 3TFlops on 64b. That's 3 times its predecessor and much more than a usual Core Cpu. Better: the new toy accesses the whole Dram directly, not through a Core Cpu, and Intel stresses its ability to run an OS directly. https://software.intel.com/en-us/articles/what-disclosures-has-intel-made-about-knights-landing In other words, one can make a Pc of it, far better than with its predecessor, and software would use the new component a bit more easily than the predecessor. This shines new light on the question: "Why do people need faster computer?" - which, for the new component, would mean: "How many people would buy a Pc built around the Knights Landing?" ---------- My first answer would be: I still want the many single-tasked operations of a Pc run quickly on the machine, but I don't want two separate main Dram in the machine so a separate Core Cpu is excluded, hence please have within the Knights Landing some good single-task ability. Maybe one tile that accelerates to 3GHz if the others do nothing. Or have one Core in the chip that accesses the unique Dram properly and slows down a lot when most of the chip runs. ---------- Finite elements are an obvious consumer of compute power in a professional Pc. 3D fields (static electromagnetism, stress...) run better and better on a Core, but 3D+time are still very heavy: fluid dynamics, convection - with natural convection being the worst. Finite elements use to run together with Cad programs, which themselves demand processing power, but less as linear algebra and more as if-then-else binaries. Fine, the Knights Landing handles them better than a Gpu does, as it runs the x86-i64 instruction set and has gotten a good sequencer. Then you have many scientific applications that may run inefficiently on a vector Cpu with slow Dram, like simulating the collision of molecules, folding proteins... These fit better chips designed with one compute unit per very wide Dram access, as I describe elsewhere. What would need a different design are databases. Presently they run on standard Pc which are incredibly inefficient on such binaries. What is needed is agility on unpredictable branches and small accesses anywhere in the whole Dram - for which nothing has improved in the past 20 years. Many programming techniques of artificial intelligence have the same needs and are expected to spread now. Web servers have similar needs too. For databases and AI, but in fact for most applications, we need the Dram latency to improve a lot, not the compute capacity. This need has not been stressed recently because neither Os, video games nor common applications require it heavily, but databases do and they get increasingly important. -
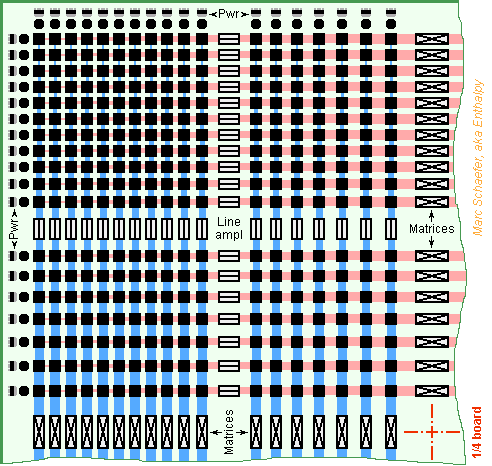
Petaflops cabinets connect already their cores together, over two dimensions on each compute board and a third dimension over the cross boards. A Google server or Tianhe-2 must connect through matrix chips the homologous nodes of all compute cabinets, adding one crossbar dimension: if 48 cabinets contain each 0.5G nodes, then the matrix chip xyz in a switch cabinet connects the 48 nodes located on board x, row y, column z of all cabinets, and there are 0.5G matrix chips in several switch cabinets. The signals, cables and matrix chips can be grouped in the big dimension without constraint from the three smaller ones. For instance, since the cross boards connect already the (horizontal) compute boards, the compute boards at height x in all compute cabinets can connect to a board at height x in the switch cabinet through cables running between height x only (and that's my plan), or one could have several switch boards per compute board or conversely. The nodes on a compute board can also be chosen at will to run their signals in a common cable to a remote switch board, provided that all compute boards choose the same nodes and the target switch board carries enough switch matrices and means to route the links. It is my plan to group 500 links in and 500 out per cable, have 500 switch matrices per switch board, and run the links from the 500 compute nodes of 5 half-rows towards a connector at the side edge of a compute board. The exaflops computer does the same with two additional dimensions of 32 compute cabinets each, as sketched on 15 November 2015. For each group of 500 nodes in every compute cabinet in a cabinet line or row, a cable connects to the common switch board, and since the compute boards carry 16 groups of 500 nodes, there are 16 switch cabinets per line and row of compute cabinet. Now, two big dimension need two connectors and cables per group of 500 nodes. Figures below refer to this option. The 40 rows of compute chips on a board (see 09 November 2015) grouped by 5 half-rows converge to 8 pairs of connectors per side edge, which the operators must plug or unplug when moving a board. Room was available at these edges, and some routing space too because the onboard row dimension runs more links at the board's center while the big dimensions run more links at the edges. Routing the compute board goes nicely for the Google server or Tianhe-2 with one big dimension, adding no layer to the printed circuit. Two big dimensions for the exaflops need more links near the edges that demand 8 more signal layers plus power, climbing to uncomfortable 28+. Printed circuits denser than 2 lines per mm, or even bigger than 1.3m, would need fewer layers. The connectors would better be capacitive. The clamping force is small, reliability is insensitive to small displacements, and the chips can manage redundancy. I prefer one electrode per link, printed on Fr4 and with several smaller chips per connector (22 February 2015), over the adaptive connector chip: the interface with the compute board or the cable defines the size anyway, and a socket for 1000 links is expensive. 2*500 links over a 40mm*40mm connector leave 1.2mm pitch per electrode, easy to align by keys and accepting some play. A sketch may follow. 20 flexible printed circuits, loosely stacked in a protective sleeve, 40mm wide to carry 50 links each, can make one cable. The boards can have the upper side's connectors for one big dimension and the lower side's for the other big dimension. All cables can bend to climb to the routing floor; 60 stacked compute board let run 120 cables superimposed, which at 6mm thickness, makes a 0.72m thick bunch; or better, have a second routing floor beneath, and send there the cables from the 30 lower compute boards. Expect 10m+ cabling thickness on each cabling floor; repair by laying a new cable. A Google server is much easier. The bunch of cables isn't flexible to take or give length to one cable, so when plugging and unplugging the cables to move a board, I plan to slip them to the side. The cables and connectors are 40mm wide to permit that in a 100mm pitch at the compute boards' edges. A description of the switch cabinets should follow. Marc Schaefer, aka Enthalpy
-
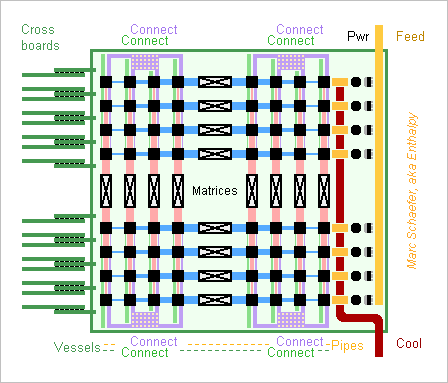
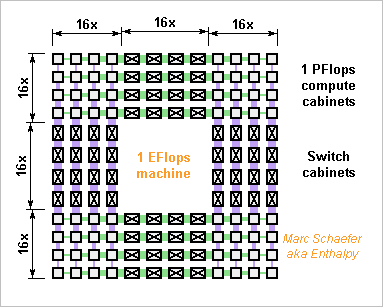
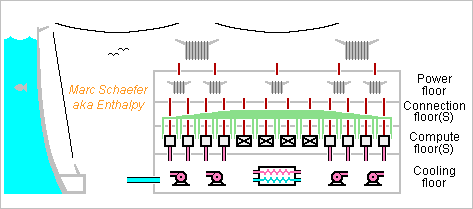
How to build an exaflops supercomputer? By interconnecting thousand petaflops cabinets. The compute cabinets follow the 09 November 2015 description, but with horizontal compute boards, vertical crossboards, and additional connectors for the two new dimensions. The clock climbs to 1.04GHz for 1PFlops. More later. 512 switch cabinets in each new dimension contain the corresponding matrix chips and shuffle the signals. Cables as described on 02 December 2013 connect the cabinets, possibly with capacitive connectors as on 12 November 2015. More later. Feel free to let the cables superconduct in their floor. 0.5G Cpu in 0.25G chips and packages carry 125PB and 16EB/s Dram and the network transports 500PB/s peak unidirectional between machine halves. Though, present supercomputers have 6 times less GB/GFlops than this Pc ratio, so if reducing the network throughput too, the machine can be smaller just with more nodes and chips per package. A DB-server-AI machine with 1.5GB, 36 nodes and 32GB Flash per package would have offered 370PB, 300EB/s, 28Eips, 280E bitlogic/s, 8EB and 50PB/s but the Web must cumulate 50PB text and index data is smaller, so a Web search engine or proxy would have one dimension less. On a single floor, the cabinets would spread over 150m*150m, so several floors would improve the latency and be more convenient. The usual Cpu figures let the machine consume 200MW. Though, more recent processes improve that, as the Xeons already show. And if the MFlops/W improve further below 1GHz, it must be done. The supercomputer better resides near a supplying dam owned by the operator. The OS must ramp the Cpu up and down in several seconds so the turbines can react. Power distribution will follow the usual scheme for the usual reasons, for instance 200kV, 20kV, 400V three-phase to the cabinets, 48Vdc to the boards, <1V to the chips. The transformers can sit all around the lighter building but this wastes some power. Cooling by liquid, as the previously described boards, makes the machine fast as hell and silent as well. With horizontal compute boards, the cabinets' design is to linder the spills - more later. The fluid can be a hydrocarbon for insulation, long-chained for high flash point, similar to phytane or farnesane; hints for synthesis there http://www.chemicalforums.com/index.php?topic=56069.msg297847#msg297847 A half Tianhe-2 would have only one new dimension, with <32 compute cabinets around 16 switch cabinets, like a Web search engine. Marc Schaefer, aka Enthalpy
-
Intel can keep the compatibility while shrinking the consumption. A single core without hyperthreading can run multitasked software as well. A scalar core can run Sse and Avx instructions, just in several cycles. Or even, the Cpu could have Avx hardware but stall the execution for some cycles to limit the consumption when vector instructions are executed. The wide registers don't cost power, only decoding the complicated instruction does, a bit.
-
Hello you all! Thermal images of pyramids, notably of Giza, show places of different inertia, suggesting something in the depth: stronger ariflow, other material, void... http://edition.cnn.com/2015/11/10/africa/egypt-giza-pyramids-thermal-anomalies/ apparently they used the day-to-night contrast and variation speed. My first suggestion would be (...if not already done!) to have a software reconstruct the matter profile as a function of the depth. To make simple, the quick reaction of a wall depends on shallow matter, the slower reaction on deeper matter. Software solves (to a limited extent) the "inverse problem", attributing more in detail matter to each depth sheath from the observation of the wall's response over time. Such software exists already for the corresponding diffusion equation; it's used at oil and gas reservoirs to estimate the reservoir volume and even gross shape from the variation over time of the pressure when the valve is opened at once. My other suggestion is to produce artificial heat input functions over time, by means of a sunshade over the day or a thermal blanket during the night, or by more artificial means. Removing the sunshade or blanket at once provides a faster varying input that gives raw data about more shallow sheaths. Putting the shade or blanket for several days lets observe material's response deeper than the circadien heat input. A step input function (Heavyside) is already more interesting than the sine-like daylight. The next improvement to gather more signal in limited time is to optimize the input function for the desired frequency spectrum. For instance frequency chirps have been used; pseudo-random sequences tend to be better. At periods slower than a day to increase depth, one would put the shade or blanket on some days and not on others, as determined by an adequate function determined for instance by a binary polynom - ask your local signal processing expert. Stopping sunlight completely to use locally an artificial heat source would allow to cover finely the depth around 24h period too, which remains otherwise fuzzy. To some extent, heating differently the varied locations of the interesting area permits a subtle software to distinguish between thick light material and thin dense one. This isn't common oilwell technology. It combines well with pseudo-random sequences. Marc Schaefer, aka Enthalpy
-
Any high-strength steel is better than titanium at equal mass. Typical Maraging steel offers 2000MPa yield strength (some offer 2400MPa) for a density of 8030kg/m3 and isn't brittle at all. Compare with Ti-Al6V4: 830MPa and 4430kg/m3. I'd love to use titanium more frequently, but it's not so exceptionally strong, and steel progresses more quickly than titanium does. A few alloys offer 1000 or 1200MPa but are really difficult to find, can't have thick sections, and other drawbacks. Tensile strength versus density is not the whole picture. At parts resisting compression or bending, buckling often demands stronger sections than the yield strength would necessitate; to some extent, intricate hollow sections remedy this but they're more expensive and can't answer everything. Then, a lighter alloy is better than steel. Problem is that aluminium alloys too are about as good (460MPa for 2820kg/m3) and are even lighter than titanium. Quite often, when steel is too dense, titanium doesn't fit neither, and aluminium is a better and cheaper solution. And of course, carbon fibre is a standard answer presently.
-
Hi Mchili, Moontanman and all, some comets are expected no to belong permanently to our Solar system. Though, stars pass by an other rather quickly in our vicinity, and an extremely remote comet orbit would be very slow, so orbiting two stars would be difficult. Earth at 150Gm from the Sun takes 1 year per orbit, so at 2 light-years (126000 times mores, half-distance to a near star) an orbit would need 45 million years. If the star's velocity relative to our Sun is 10km/s it drifts by 1500 light-years in this time so it's no more our neighbour.
-
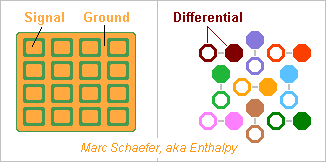
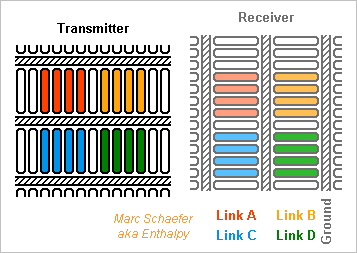
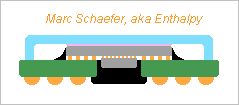
Chips can transmit signals capacitively, as I described on 22 February 2015 (second message). These chips can also transmit differential signals if any better, and optionally use the pattern I described on 24 November 2013: I proposed that my data vessels use capacitive coupling; the cables made of flexible printed circuits I proposed on 02 December 2013 can also use capacitive coupling instead of electric contacts. As capacitances accept some distance between the electrodes, the connectors for hundreds of contacts are easier to make and more reliable. I'd keep active redundancy. The ends of the cable can be stiff: stack glued together, or a piece of stiff printed circuit or ceramic hybrid circuit there. On 23 February 2015, I proposed capacitive coupling chips that are adaptive to transmit hundreds of signals over a small area and accept imperfect alignment. Such chips look useful at connectors for many-signal cables, and at data vessels maybe too. Marc Schaefer, aka Enthalpy ============================================================================== Integrating the Dram and the processors on one chip is the good method but adapting the process may be costly. As an intermediate step, two chips made by different existing processes can be stacked in one package: For the machines I describe, the processor(s) are smaller than the Dram. If Intel or Amd add one Dram cache chip to their processors, this Dram will be smaller. This needs many signals. For instance, supplying 4* 64b at 1GHz from a 15ns Dram needs to access 480 bytes at a time. Stacking the chips passes many signals more easily than cabling them side-by-side on the package. The signals can be faster than 15ns. At 1GHz "only" 256b per node are necessary. Intel and Micron have such plans, for several Dram chips per package. Two nodes with 256 signals plus Gnd still need 1.3mm*1.3mm at 40µm pitch. Twelve nodes need more. Possible but not pleasant. The signals can pass capacitively. A PhD thesis exists on the Web on this topic. This won't ease the alignement of the chips but improves the production yield and reliability as it avoids to make hundreds of contacts simultaneously. My scheme for adaptive connections between two chips, described on 23 February 2015 (drawing reproduced above), does ease the alignment of the chips, hence permits denser connections. It can use capacitances or contacts similar to flip chip methods, with reflow material brought on the lands (pass the Gnd elsewhere). Between two chips, have redundant signal paths and choose them after assembly or after reset. Marc Schaefer, aka Enthalpy
-
Relativistic corrections to hydrogen-like atoms
Enthalpy replied to Enthalpy's topic in Speculations
This curve relates: - The deviation from Z2 of the last ionization energy, for nuclei of varied Z; - With the kinetic energy of the electron over its rest mass. Here's the spreadsheet: RelativisticHydrogen2.zip The ionization energy is from C.E.Moore: Ionization Potentials and Ionization Limits Derived from the Analysis of Optical Spectra (1970) obtained over the CRC Handbook of Chemistry and Physics, 72nd edition section "Atomic, Molecular and Optical Physics", chapter "Ionization Potential of Neutral and Ionized Atoms". The data I got previously over Webelements.com is uniformly 23ppm bigger and must have the same source. The only correction ("pinned") included so far is the electron-to-nucleus mass ratio. For instance the nucleus' size is not included. I see on this curve that - The kinetic energy contributes to the deviation: 1% kinetic energy vs rest mass increases the ionization energy by 0.46%, nearly the 50% expected from the increased mass+energy. - The electrostatic energy doesn't contribute much to the inertia. I expected it would, reducing it. - The experimental points fit a straight line very neatly, suggesting that the 0.50 and even the 0.46 are significant and don't result from higher powers of E/mc2. Comments are welcome of course, additional datasources too. Marc Schaefer, aka Enthalpy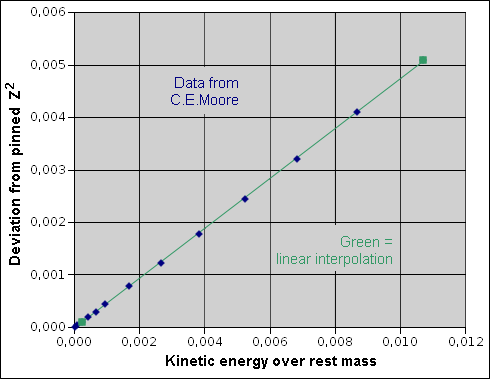
-
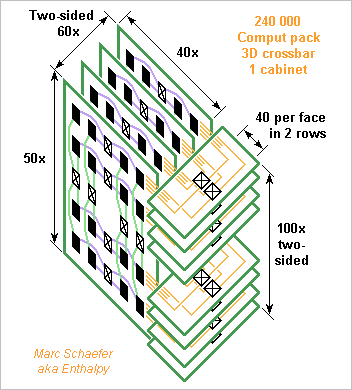
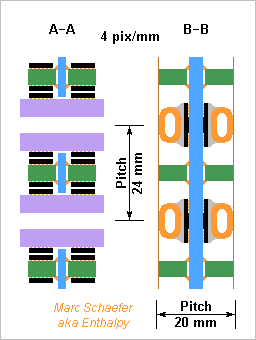
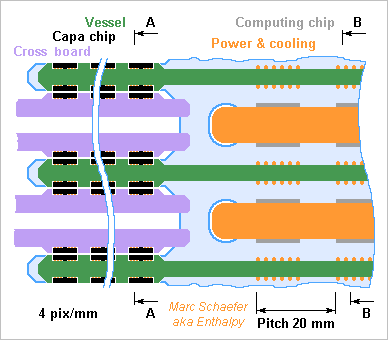
Here's a one-cabinet machine with crossbar. It carries 240 000 computing packages, so with a two-node chip per package it crunches 0.96PFlops in 120TB Dram while the 3D crossbar carries 480TB/s peak between machine halves. As a DB-AI-Web machine, it depends on how many nodes shall share the limited network. Three 12-node chips and 32GB Flash per package (sharing two link pairs per dimension) offer 360TB and 280PB/s Dram, 26Pips, 260P bitlogic/s, 7PB and 48TB/s Flash. The cabinet is about 1.5m wide, tall and long. No repeater is drawn here, the data vessels neither. At the computing boards' edge opposite to the cross boards, the cooling pipes are insulated and converge to the board's fluid feed at the lower corner, while low voltage injected in the pipes is made near this edge from 48Vdc received at the upper corner. The compute boards carry two network dimensions. At 20mm*24mm pitch it takes ~16 layers. A board is 1.2m tall and 0.9m long without the supply, matrices, repeaters. Strong Mylar foils protect the components when inserting and extracting the boards. Two 4mm*7mm data vessels per package line carry each 80 signal pairs in 14+15 layers. 2*6 chips on each vessel exchange the data capacitively with the cross boards. The cabinet has two crossboards per package line. They're 1.2m long, and 25 layers make them 0.3m wide. Each face carries 40 matrices, for instance in two rows. Through 1.2m*0.3m section, the crossboards carry 240k pairs of quick signals. That's 0.75mm2 per signal, and improvement is desired. Fibres would outperform with dense wavelength multiplexing, but then the filters shall be tiny, thanks. The hypercube of 01 March 2015 brings 2PFlops but the crossbar machine could have 2GHz clocks too. Instead of 0.9MW, the crossbar machine takes 200kW and is smaller, with better latency and fewer collisions. Marc Schaefer, aka Enthalpy
-
The Transputer was too advanced for its time - both versus the designers' habits and versus the technology needs. 30 years laters, its choices would be the good ones. ---------- Then, external Ram delivered data at the processor's pace and without delay, so the Transputer's integrated Ram wasn't seen as an advantage. Quite the opposite, it was felt as a loss of flexibility, and the alliance of fabrication processes that would make neither a good Ram no a good Cpu. Meanwhile, Cpu have accelerated muuuuuch more than the Ram, which delivers neither a decent access time (150 cycles for a word!) nor even the throughput. A four-core Avx256 that just accumulates at 3.5GHz many products from two vectors needs 112G words/s while a four-port Pc4 27200 delivers only 109GB/s, eight times less. On-chip cache improve the latency, but they give throughput only if the program accesses repeatedly the same small data. If linear algebra software (which is already a very favourable case) is programmed the traditional way, going linearly through the data, then it keeps steppig out of every cache level, and gets limited by the Dram throughput. To get performance, the programmer must cut each loop in smaller ones and reorganize the computation to reuse many times the data already in L3, and possibly do the same at L2 size, L1 and the registers. The old "golden rule" of equal throughput at every memory level has been abandoned, and this has consequences. Then you have applications like databases which have to sweep through the Dram and not even at consecutive locations. They just stall on the present memory organization. Add to it that each core needs vector instructions to run as it can, and that the many cores need multitask programming, and you get the present situation at Pc, where very few applications (nor OS) make a somewhat decent use of the available capability. Some video games, image and video editing software, a few scientific applications - that's all more or less. Present supercomputer are worse, as their network is horribly slower than the Cpu, so multitasking among the sockets must be thought accordingly. Also, they often add hardware accelerators that are binary incompatible with the general Cpu and introduce their own hard limits on data interchange. You get a many-million toy that is extremely difficult to use. I believe something new is needed - and users seem to push too. Then you have the emerging market of databases, web servers, proxies, search engines, big data. Present Pc are incredibly inadequate for them, but the servers are only a bunch of Pc put loosely together. These may be the first customers to wish different machines, and accept to change the software accordingly, even more so than supercomputer users - that's why I describe such machines every time. Remember the worldwide eBay fitting in an Atx tower. ---------- One design feature here is to put the Dram and the Cpu on the same chip. The Dram fabrication process may be suboptimal for the Cpu, it may need some development, but this is the way to an access width like 500 bytes that provides the throughput for just one scalar core. As well, a smaller individual 250MB Dram for a 1GHz scalar core is faster (shorter lines) than a 1GB chip shared among 4 Avx cores; its protocol is also simpler. And once on the chip, the Dram easily offers much-needed access capabilities like scaled and butterfly addressing at full speed. I also suppose (to be confirmed) that Dram manufacturers feel presently no pressure to reduce latencies. Within the L1 L2 L3 Dram scheme, their role is to provide capacity, which is also the (only) data customers care about. But it also means that progress can be quick if a computer design puts emphasis on Dram latency; maybe it suffices to cut the Dram area in smaller parts, accepting to waste a little bit of chip area. Intel has recently put a separate Dram chip in the package of a mobile Cpu. The benefit isn't huge, because the Cpu fabrication process made a small and power-hungry Dram serving only as L4. Intel has also revealed plans to integrate Micron Dram on the socket; this solves the capacity and power issues, but not the throughput nor latency, which need the bus on the chip. Also, the present organization with several vectorial cores on one chip need several Dram chips to achieve the capacity per MFlops. My proposal instead is to have just 1 or 2 scalar Cpu per chip, and then all the corresponding Dram fits on one chip. The equivalent Dram capacity and processing power fit on the same number of chiips, just better spread. While Intel can certainly develop a Dram process, alone or with a partner, going back to a single scalar Cpu seems to imply a loss of compatibiilty, so I'm not sure (but would be glad) that the combination I propose will evolve from the 8086 architecture. Mips and Arm are contenders - or something new. ---------- The transputer had 4 serial links - if I remember - like present server Cpu, to connect directly 5 Cpu, or make a 16-node hypercube, etc. Later Inmos proposed a 32x32 crossbar among the serial links for a 32-node machine with a good network. One could have made a 324 = 1M multidimensional crossbar from these components, but I didn't read such a dscription then. One possible obstacle then was that big machines had slice processors that cleanly outperformed microprocessors. The already older Cray-1 provided 80M mul-acc per second from one pipelined Cpu; this was achieved just from vectorial programming, already on short data. As opposed, microprocessors took dozens of cycles at 10MHz just for a double multiply. Why would have users of linear algebra gone to heavy multitask parallelism then? The Dec Microvax was the fist (monster) microprocessor to outperform MSI circuits in a minicomputer (not a supercomputer) and it appeared years after the Transputer. Presently the only way are complete Cpu integrated on a chip, and the only way to get more processing power is to put more processors. Possibly vector ones, with a faster or slower clock for consumption, but basically there is no choice. And because data transfers a slow among the chips, extensive parallelism results only from loose multitasking - no choice neither. That's why I propose that parallelism results from loose multitasking only. Not from small vector capability, not from a complicated scheme of caches shared or not with difficult consistency. Instead, have just scalar Cpu with a good Dram each, and a good network, so that massive multitasking is the only programming difficulty. ---------- What shall be the network topology? Well, anything feasible and efficient. Because in a machine with one million or half a billion nodes, some hardware will be broken at any time and the tasks reallocated to other nodes, so the application can't depend on topology details: the application defines a bunch of tasks, the hardware or the OS defines where they run and finds which node has the data an other seeks. So the conceptual ease of use by the programmer isn't important; only the performance is. Though, a dense network is difficult to build for many million nodes. Supermachines are essentially a matter of cabling - hence the thread's title. 1D crossbars are excluded. Hypercubes have been built but are difficult at big machines. Present supercomputers have a fat tree - which is a multidimensional crossbar that abandoned its ambition - or more often a hypertorus, which wouldn't be bad by itself, but is always far too long because of cabling constraints. One hard limit of present supercomputer is that they use fibre optics, and even Ethernet, for connections. Because the connectors are huge for just a single signal, the networks offer a ridiculous throughput. Pc technology is just inadequate. That's why I propose: The cables made of flexible printed circuits and their connectors (see 02 December 2013) that transport 512 signals; The compact capacitive connectors among crossed printed circuits (see 22 February 2015); The signal vessels (see 02 February 2015) to drain data to the board interfaces. I too would love to have cables with 1000 fibres and connectors 40mm wide and 10mm high, but up to now I've found credible solutions for electric cables only. With such routing hardware, topologies become possible beyond the cramped hypertorus of a few fibres. With hypercubes I could go nearly to the Tianhe-2 size, and very cleanly (printed circuits only) to 2TFlops. With multidimensional crossbars I hope to go farther, as they need fewer contacts at the chips and boards, but the routing density of printed circuits limits the machine's compactness. At Tianhe's capacity, a good network is possible. For the exaflops machine, let's try.
-
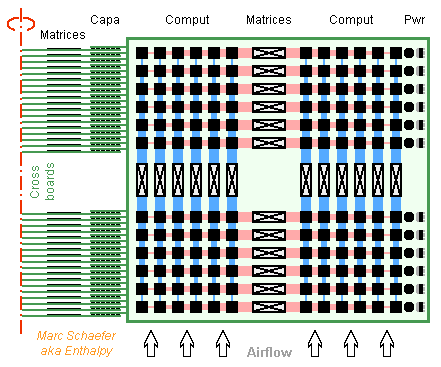
Hi MigL, thanks for you interest! Answering soon. ---------- Drawing for the 2kW AI machine (and database, web server and so on). It's compact: D=0.8m h=0.25m plus casing, supply, fan. For a 2kW machine, 35µm supply planes distribute the current, and 0.2m/s air speed cools the machine. But a 26kW number cruncher better has liquid cooling, and the pipes distribute the current as well (see 01 March 2015); two data vessels per line fit more naturally then. When power isn't a limit, the cross boards can easily grow to accommodate more compute boards. The compute boards can grow too, but they lose density. Marc Schaefer, aka Enthalpy
-
This is a 2kW machine for artificial intelligence - and databases if much network throughput is wanted. Without awaiting the drawings because the spooks have already stolen this idea from me, codeword "en même temps". The 3D crossbar accessed individually by the 65k nodes consuming 30mW each makes the machine bigger than the nodes would need. Each compute package holds just one chip of 12 nodes optimized for AI & DB with 40MB Dram per node, the compute boards have packages on one side only, and the compute boards hold only 12*12 compute packages or 1728 nodes; 52W per board are easy to supply and air-cool. At 18mm pitch, 6 compute packages send 72 and receive 72 links to the 72x72 switch component; the 2*12 switch components are at the two midlines of the array as previously. A standard 2D crossbar would have approximately 2*42 switch components of 21x21 capacity, but the 72x72 ease routing and offer more paths. The board has 6+6 signal layers plus 3 Gnd and 3 Vdd - more layers shink the machine. A compute board is 250mm high, a bit wider for the supply at one end. The compute boards bear 3 data vessels (see 08 February 2015) per line of compute chips, or 36 vessels carrying each 48 links in and 48 out. The vessels are 7mm wide so 8 signal layers and 8 power planes suffice. Capacitive components (see 22 February 2015) couple the links at the vessels' ends, for instance 2*3 chips of 16 signals each, or more for redundancy. The machine comprises 38 vertical compute boards and 36 independent horizontal crossboards that make the matrix' third dimension that switches homologous nodes from each compute board. Each crossboard has 48+48 links with each of the 38 compute boards. It can carry 24 switch components of 38x38 capacity - or for instance 12 components of 76x76 capacity which can be the same small chips as for the compute boards, repackaged if useful. The D=200mm crossboards could have 12 to 16 layers, more difficult to estimate. Round crossboards surrounded by compute boards are more difficult to service but they ease routing, shorten the latency and avoid repeaters here too. One fan can cool the spectacular design. With 2GB/s links, the network carries 65TB/s between machine halves. 4 cycles per 64b word for each node, that's comfort for Lisp-Prolog-Inference engines. ---------- If someone feels a 2kW database needs this network throughput, fine. The 2.7TB Dram capacity can then increase if useful, with 6-nodes chips on both sides of the compute boards, or stacking three 2-nodes chips per package for 16TB... Plus the Flash chips, necessary for a big database but optional for AI. Or an AI+DB machine can keep this network but have 12 nodes per chip, stack 3 chips per package on both board sides. The 394k nodes consume 12kW, are rather liquid-cooled but offer 16TB Dram and compute 1.2Pips. Ill-defined machine size, limited neither by the power nor the connections. A number cruncher with two 256MB nodes per chip would stack 3 chips per package at each board side, since I feel one word in 4 cycles is enough from the network. The liquid-cooled 65k nodes machine draws 26kW and offers 130TFlops, 16TB Dram: 1000 times a Pc in a small box. Marc Schaefer, aka Enthalpy
-
That doesn't need any citation, because I know it from memory with perfect accuracy, as does anyone from that time. Fact is that Intel and the others have rewritten Moore's law afterwards. That they spread their lie over Wikipedia and everywhere doesn't make it true. And you know what? I have no intention to justify myself for telling the truth. If you believe any lie just because it's repeated, that your problem. Thanks MigL! I'll definitely have a look.
-
Why do people need fast/strong computers
Enthalpy replied to silverghoul1's topic in Computer Science
On this diagram of a Skylake die, I show what is useful to me. Intel won't be delighted with it, and Amd neither, but this is what I really need. Maybe a third player gets inspiration from it? I don't need the graphics processor at all, nor the display controller. I don't need three of the four cores. I don't need three-quarters of the 256-bit Avx. I don't need hyperthreading nor the Sse and Avx instruction set extensions, so most of the sequencer can drop out. Not represented on the diagram, but that's much area, power, and cycle length. How much L1 and L2 do I need? Do I need an L3? Unclear to me. The Usb links do not need to be on the Cpu. But I do need a good Dram and Pci-E interface. So of the execution area and power, I use 1/10th to 1/30th. The rest of the die consumes far less and can stay as is. The Core 2 added already much hardware useless to me but it did accelerate my applications a lot. Since then, progress is minimal, like 25%. Could that possibly be a reason why customers don't buy new computers any more? For new applications, a few editors and programmers sometimes make software that uses several cores and the vector instructions. Better: compilers begin to vectorize automatically source code that would be vectorial but is written sequentially - excellent, necessary, and it begins to work. Fine. But I want my to accelerate my old applications. I don't have the source, the authors have changed their activity - there is no way these get rewritten nor even recompiled. Sorry for that. That's why I suggested that a magic software (difficult task!) should take existing binaries and vectorize them. It's not always possible, it's a hard nut (artificial intelligence maybe), it may produce wrong binaries sometimes, but this would take advantage of the available Sse and Avx. The much better way would be that the processor manufacturer improves the sequencer to run several loop passes in parallel. This too is difficult for sure since the sequencer doesn't have as much time as an optimizer to make smart choices, but it would apply to binaries that can't be modified. The Skylake has hardware for four 64b mul-acc (in just one core), and a better sequencer would eventually take advantage of it. Even better, this would work on an OS that isn't aware of the Avx registers. Hey, is anybody there?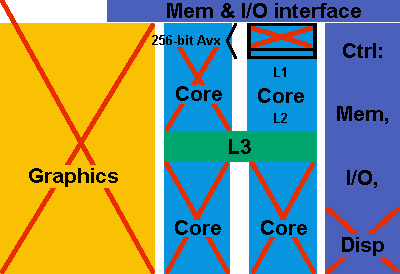
-
Moore's law has been dead for two decades. It stated "double the number of transistors and the clock speed every year". Intel has rewritten it "double the number of transistors every 18 months" to claim that stick. I was in the job at the 4µm era during the upper paleomonolithic (when Vlsi meant dense - meanwhile we had Ulsi long ago, adn seemingly this naming series was abandoned for lack of hypes). Already then and meanwhile, many people got famous for a quarter hour by predicting the end of the progress, including at 1µm "because of fundamental physical limits" that have all been smashed. A few hard nuts presently: - Oxide thickness can't really go down, and did I read that it didn't go down recently? - Lithography can't stay indefinitely at hard UV. Last time I checked they used 146nm vacuum wavelength, in full high-index immersion, with short focal lenses, and diffraction-correcting masks, to achieve 34nm line width then. At some point the game will be over, needing a different source. But if needed, electron beams have been available for decades. - The supply voltage can't go much down. It's already below one bandgap, meaning that the Mos are never well on nor well off. So the clocks don't improve, the consumption improves too slowly, and the Cpu gain speed only through more parallelism - and that's the real problem, because this kind of parallelism brings nothing to existing software. Presently the Core is an absolute dead end. For my applications, it has made zero dot nothing progress since the Core 2. The ways out don't need better semiconductor processes: - Develop processors that exploit the present vector or parallel hardware on existing sequential binaries. By far the best solution. - Develop some magic software that rewrites existing sequential binaries (ignoring the source) to exploit the present parallel hardware. - Less good: have compilers that parallelize the binary even if the source isn't optimized for. At least new software will run faster. Most programmers have done strictly nothing for that despites the Sse dates back to the Pentium III and multicore to the P4. - More probably, smart phones or supercomputers will promote processors that are uncompatible wit the 8086 and run more efficiently. The OS and applications written for them will be new and hopefully meant for parallelism. As for semiconductor processes, the way out of the limits may be 3D - but what manufacturers call presently 3D is only stacking. Unless, of course, something new works better than ever-smaller silicon, be it graphene or something else.
-
A Pc's coprocessor installed in a worker's office should fit in a box and draw <2kW - blow the heat outside. A Pci-e board in the Pc can launch the links to the separate box. ---------- Number cruncher 5184 nodes with one 0.4W double precision mul-acc at 1GHz provide 10TFlops and 1TB from 200MB at each node. Exchanging with the cache sixty-four 64b words in 15ns from 127 Dram banks provides 4 words per cycle to the processor, or cumulated 177TB/s. A two-dimensional crossbar of 722 nodes is still feasible on a single Pcb. The 72x72 switch components fit in a (4+4)*40 Bga, the network has 2*72 of them. A 12mm*12mm package can host two nodes on one chip or two. Line amplifiers every 200mm enable 20Gb/s on a link to transport 5.2TB/s peak unidirectional between network halves. The network brings one word in 4 cycles to a node. Imagine an algorithm where a node imports N words to make just N*Log2(N) complex mul-add on 32+32b in as many cycles: N=16 chunks suffice to keep the node busy - that's comfort. Two nodes per package at both Pcb sides need only 36*36 sites split in four 18*18 sectors (one sketched here) by the switches cut again by line amplifiers. The rows can connect complete packages and stay at one Pcb side while some lines connect the A nodes of packages at both Pcb sides and the other lines the B nodes. Nearer to the Pcb centre, the line and row pitch widens to route the more abundent links. The last crossing passes 144 links (from both Pcb sides) in 25mm pitch over 4 signal layers plus 4 layers for the cross direction, so <12 signal and 6 supply layers must suffice. At the switches, minimum 16mm pitch permit to route 72 links in 8 signal layers over 10mm available width. The Pcb is 0.85m*0.85m big. Supplying estimated 0.6V * 3456A isn't trivial, but with converters on all 4 edges, 3+3 supply layers, 105µm thick, drop 8.5+8.5mV. Busbars can do the same, at one Pcb side per direction. Or aluminium heat spreaders, as big as the board and 10mm thick including the fins, can bring Vss at one side and Vdd at the other, dropping 5+5mV if fed at one edge. Or a flat supply can hold the Pcb by many spacers and screws that inject the current; in that case, stacking two chips usefully brings all computing packages to the unique heat spreader at the opposite side. ---------- Database and artificial intelligence engine Keeping the network and Pcb designs, each computing package can host 24 simpler nodes consuming 30mW instead of 2*0.4W. Two stacked computing chips hold each 12 nodes with individual 40MB while an Slc flash chip adds nonvolatile 32GB for total 62k nodes, 2.5TB Dram at 2PB/s and nonvolatile 83TB at 500GB/s (many ports would improve). 5ns Dram latency would permit 12T random accesses per second and three units for cascaded logic 2P bit operations per second. Though, the network keeps 2 in + 2 out links for 24 nodes per package now, and while this should suffice for a database, I feel it would restrict the style of artificial intelligence programs, so a special machine would look rather like the multi-board ones I plan to describe. Marc Schaefer, aka Enthalpy
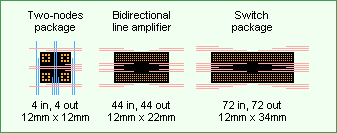
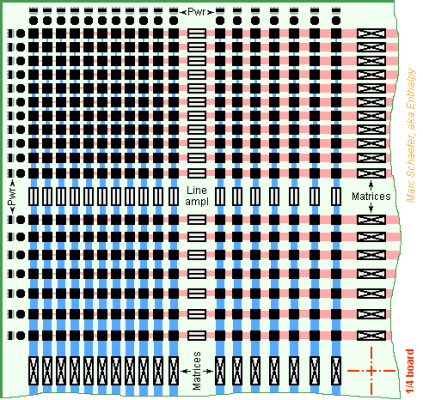
-
Aggiornamento to the node's computing capabilities for a database or artificial intelligence engine. Outside signal processing and linear algebra, most programs spend the time on small loops that contain condition(s), so a second flow control unit is a must. To save power, this one can compare and branch but not add. Consuming 86 units more than the previous 800 is extremely profitable: 5% slower clock but 1 cycle less in most loops. An instruction "Subtract One and Branch" (if no underflow) can often replace more complicated loop controls. Special hardware used by the compiler when possible instead of the heavy flow control would save M$ electricity on a giant machine. During a lengthy multiplication, flow control instructions are less useful. Excluding them gives power for a bigger 32x14 multiplier that saves 4-6 cycles on big products. Marc Schaefer, aka Enthalpy
-
A database or artificial intelligence engine on a Pci-E board with crossbar can resemble the previous number cruncher, with adapted computing packages. 3 stacked chips in the 352 package combine Dram and data processing for 528GB Ram per board. This defines the quickly searchable volume of the database - text, not pictures - or the work memory of an artificial intelligence program. At least the database gets Flash memory too. Slc is more reliable, swifter, and present 32GB chips read and write 200MB/s. One chip stacked with the computing chips sums 11TB and 70GB/s over the board. 20 times the text contain the images of a typical Web page, while Mlc would quadruple the capacity, and more chips can fit in the (optionally separate) packages. Databases and artificial intelligence have similar needs: branches and data access badly predicted, many conditional jumps, simple integer operations, but few multiplications nor float operations. This fits neatly with many simple low-power nodes, each with a smaller hence faster Dram, a slower clock and a short pipeline, while complicated operations can take several cycles. Here under artificial intelligence, I mean programs that combine fixed knowledge in myriads of attempts, often in Lisp or Prolog. These are naturally many-task and fit nicely the parallel machine. Other artificial intelligence programs, especially machine learning, look much more like scientific computing and fit rather the previous number cruncher. To estimate the power consumption of a node, I compare the number of complex gates (full adder equivalents) with existing chips which are mainly float multipliers: not quite accurate. The reference is a 28nm process graphics chip, whose 1000+ gates draw 67mW per 32b multiplier. A 14nm process for Cpu would supply the sequencer too and everything from that power, but the present machine emphasizes Dram, whose process is suboptimal for a Cpu. Shift-add would multiply too slowly to my taste, hence the 32b*8b multiplier-accumulator. Useful by itself, it also makes the bigger products in several steps, quite decently on 32b. It consumes more, but for random jumps and data access I want anyway the condensed flow control hardware (add, compare and jump) and multiple scaled indexed addressing, so the node has 3 of the other execution units. The 3 Alu can operate on distinct data or be chained at will within one cycle, like s ^= (a << 3) & b. This nearly keeps the cycle time defined by other units. The 3 cascade bitlogic units do each a 10-bit arbitrary operation I proposed here on 26 February 2015 and are independent. The 3 find string units search for substrings at any byte offset, their output can be coupled like "react if any finds something". The sequencer shall permit flow control and addressing in parallel with computations, but stall for instance the Alu when the multiplier draws power. 36mW each permit 12670 computing nodes at 1GHz as 36 nodes per package on 3 chips. The board's Alus and cascade logic provide peak 38Tips and 380T logic/s (PC *103 and 104) and the multiplier decent 2.5TMacc/s on 32b floats (PC *101). Each node has exclusive 40MB Dram. The small units shall operate in 4ns. Exchanging 16 eigth-bytes words with the cache provides the mean 4 words per cycle, while 17 banks avoid collisions at the butterfly and scaled datamoves described here on 19 November 2013, useful to process one field from a database. The Drams cumulate 400TB/s and 3T random accesses per second (PC *104 and 105). A Flash chip reads or writes one Dram in 0.2s so swapping gets conceivable, but I'd prefer one Flash port per node. The network keeps one link per package, dimension and direction as for the number cruncher: it carries 530GB/s peak unidirectional between network halves. Marc Schaefer, aka Enthalpy
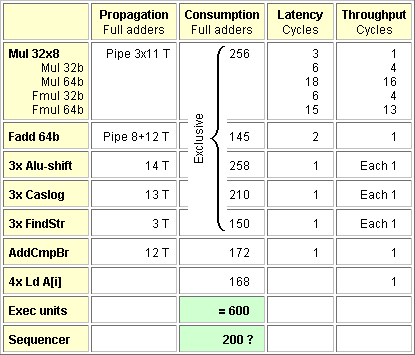
-
Why do people need fast/strong computers
Enthalpy replied to silverghoul1's topic in Computer Science
Yes, I certainly agree there are technological reasons to limit the clock frequency, as semiconductors were my first occupation. Graphics cards go even further by running at 1GHz, since for them, parallelism is easy and consumption is the limit. It's just that... I can't do anything with the multicore nor the Avx, because they don't fit my applications, and these won't evolve. There is some headroom, though, because processes have improved. It doesn't always need longer pipelines and their drawbacks. Present Cpu have 6 cores with Avx256 at 3.4GHz: that's 24 units on 64b floats able to work simultaneously without burning - plus the graphics coprocessor now. If power were the only limit (it's not), the law in F2.40 would permit a single 64b unit at 13GHz. Just for completeness, the A64 wasn't the first Cpu to execute several operation in parallel. My Pentium-1 could already work on load/store, loop and numbers simultaneously, though less perfectly than the Core, and it had already 2 Alu that did compute simultaneously. At that time, I measured 2 or 3 cycles per loop pass containing many instructions. And while the Core has indeed a pipe length similar to the P3, it's a (excellent) redesign from scratch. Where the P3 took 2 cycles for a mul, the Core does a mul-acc per cycle, and it emulates the Mmx instructions on its Sse hardware while the P3 had both. But the Core's subtle sequencer owes the P4 very much, with decoded instructions in L1 and micro-ops. I put much hope on a parallelizer for existing machine code. That would be perfect. I'd even spend money on a many-core Cpu then. ==================== One heavy trend in the near future is artificial intelligence. Be it useful to the consumers or not, it will spread to home PC just because companies begin to use it on supercomputers (search the Web for Yann Lecun), so it will be fashionable and programmers will seek consumer applications, possibly find some. Different kinds of job need different capabilities from the machine. In addition, the necessary computing power is hard to predict. AI programmes can apply established knowledge on a new situation. These are for instance expert systems. Their computing need range from moderate to unobtainable; for instance language translation should need speed. Such programmes typically process addresses and make comparisons, make unpredicted jumps in the programme and the Ram, but compute little on floats - even integer multiplications are less common. Or they can infer new knowledge from a set of observations, aka "machine learning", for which neural networks seem to be still the standard method. Its needs resemble much scientific computing, with the optimization of linearized huge sets of equations. Yann ran the first attempts on a Cray-1, and now machines like Blue Gene begin to make sense of big amounts of data, like abundent sets of pictures, or scientific papers. It's the kind of programme I had in mind when asking to find the pictures featuring Tom cat but not his fellows. While PFlops at home must wait a bit, TFlops are already available in Gpu or nearly, and much more is possible at a small company. For machine learning, more Flops mean learning more subtle knowledge, or from a bigger observation set. -
Why do people need fast/strong computers
Enthalpy replied to silverghoul1's topic in Computer Science
I'd like from my OS or file navigator these easily paralleled tasks : Find all text files that resemble strongly a given one - including txt, rtf, doc, htm... optionally across different types. That is, I designate one text file, the navigator finds all files in a big folder (10,000 files) that are probably edited versions of the reference. More in detail: some text portion can have been added, erased, moved within the file... Find all images that resemble a given one. In a first approach, "resemble" can mean: cropped, scaled, rotated by multiples of 90°, changed contrast and luminosity. And of course, among varied compression methods. Consider that an amateur photographer has many 10,000 pictures. And in a later approach, "resemble" would mean: "find all my pictures where Tom cat is" - not mistaking him with his fellows of course. Do it as you want, I'm the idea man. You wrote "fast computers", didn't you. ========== Above all, I'd like computers to run sequential applications faster. I know this is what Intel and Amd do not want to read, sorry for that, but my demanding applications were written for DOS and 8086/8087, received later a Windows graphical interface, and nobody will rewrite them in a foreseeable future. This includes chemical equilibrium in rocket chambers, molecular conformation. The stone-old code is single-tasked and uses no Avx nor Sse. So I have no reason to buy a 3.3GHz twelve-core with Avx512, but I'd be happy with a machine as cycle-efficient as the Wolfdale, even without Sse, at 6GHz or 15GHz. Though, maybe the sequencer can further improve the parallel execution of apparently sequential code? Both pieces of software I give as examples are optimization problems, which are linearized then solved step by step. Implicitly, the code is hugely parallel - it only was written as sequential loops historically. The Wolfdale's sequencer already achieves one multiplication-accumulation per cycle on such code, hence it does the condition test, index incrementation, jump, data read and write in parallel to the float computation, taking nearly one cycle per loop. That's 3 to 20 times better than the Tualatin, and the Ivy Bridge gains further 20%. The step beyond would be that the sequencer unrolls loops to exploit parallelism among successive passes where available. Seemingly the Cores still don't do it, and this would bring them beyond one pass per cycle. The compute hardware for that is long available and unused, including for software not relying on float calculations. Unrolling the loops would normally be the compiler's job, but these applications provide only the executable. An other technical option would be an optimizer that reads the sequential executable and produces a parallel version of it for the Sse and Avx; a legal difficulty is the copyright of the executable. Such an optimizer could also seek multitask parallelism in executable code. This is less easy and potentially unsafe. It could check for instance if functions can run independently from an other, then send the multiple calls to new tasks on different cores. Or cut millions of passes through a loop in 100,000s written as new tasks. This difficult optimizer would better be programmed using artificial intelligence style. Marc Schaefer, aka Enthalpy