Enthalpy
-
Posts
3887 -
Joined
-
Last visited
-
Days Won
1
Content Type
Profiles
Forums
Events
Everything posted by Enthalpy
-
About random codes: most authors understand it as codes chosen randomly. This was not my intention. Here I meant: codes strongly optimized, that follow no theory (no BCH for instance) hence have no efficient decoding algorithm. For instance, a BCH(15,7,5) is less than optimum (never believe a textbook) as its 2*4 bits redundancy suffice to distinguish two errors at positions (i,j) from (j,i) which is useless - but it has a decode algorithm. As opposed, my old software (found it again, but too long to adapt to other sizes) finds codes(16,8,5) which have a more convenient size, are more performant - but have no general decode method. While decoding tables have 256 bytes for the codes(16,8,5), they're impractical for bigger codes. By the way, my (16,8,5) aren't bad when soft-decided and combined with a 255 bytes long Reed-Solomon; easy job for a computer. If the Reed-Solomon can correct 26 errors, the combination gains 9.8dB over a codeless Bpsk, while an 18 errors capability is only 0.1dB worse and 15 errors 0.2dB. With this "short" Reed-Solomon, an additional external code seems to bring something. It wasn't the case with 4095 symbols. This is less than Golay's 11.1dB, partly because the code is smaller, and also because the (16,8,5) isn't perfect: it approaches (16,8,6), soft-decoding takes advantage of it but this is neglected here. Bigger theoryless codes are thus interesting.
-
I suggested on 18 September 2012 to run a so-called "soft-decision" on block codes like Golay and this spreadsheet finds a seducing sensitivity SoftBlockReedSolomon_v1.zip A Reed-Solomon code that corrects up to 209 errors in 4095 12-bit words combines with soft-decision of a block code, here an extended Golay with its 12 bits information. The Reed-Solomon would lose just 0.1dB if it can correct 102 errors, 0.2dB for 72 errors. I compare the receiver's sensitivity with a Bpsk transmission of same error rate without correction and same information rate (since the redundancy increases the receiver's bandwidth hence noise, many books err at this point), and The soft Golay fills 45% of the throughput with information but gains 11.1 dB, wow. The Reed-Solomon alone would gain 8.6dB, a soft-decoded Hamming(18,12,4) 9.3dB. The extreme case Hadamard(4096,12,2048) would gain 12.8dB but fill very little. On a block code, soft-decision simply permits to integrate over a longer time (the code distance) the differences between the codewords and obtain a complete symbol. This makes the gain, despite the result must be distinguished from many neighbour codewords. I didn't compare the figures with a turbo-decoding scheme. A Golay here isn't so big but it combines nicely with the Reed-Solomon, and its soft-decision is optimum. Maybe I find again my old software to produce so-called random codes. Since no decoding method is needed, they fit well here. A code longer than Golay may be useful, and some with more than 12 bits information too. ---------- Correlating the 24 received sample with all 4096 codewords of a Golay to decide the best symbol takes 98e3 Mul-acc if squandering a processor's multiplier for the +1 and-1; just use conditional add if it's faster or saves power. Alternately, we could precompute all sums and differences for groups of four samples for instance and only combine these precomputed values, or make even more subtle tricks, but this fits an Avx or Gpu less well and may be slower. A clearer option is a special chip that adds many small integers conditionally; with unoptimized 4096 adders on 20 bits it soft-decides a symbol in 24 cycles. A 2.5GHz dual-core Sse achieves 20e9 Mul-Acc/s on 32b floats to make the soft-decision for 200e3 symbols/s or 270kB/s information. Two 3.5GHz six-core Avx (336e9 Mul-Acc/s) soft-decide 4.6MB/s. One video card (Gtx 750 ti: 653e9 Mul-Acc/s) soft-decides 9MB/s. Two video cards (Gtx Titan Z: 8122e9 Mul-Acc/s) soft-decide 123MB/s. So while the Gpu isn't always necessary, it enables a higher data rate or a cheaper computer. Bigger codes, which gain sensitivity, need much more compute power. Marc Schaefer, aka Enthalpy
-
But now the first page of this thread is accessible, probably through the magic intervention of our dear mods. It looks like the names of the thread pages evolved few years ago, and neither Google nor some indexes here followed that change.
-
Thanks for your input! Changes over very few months, as the update to the latest study attempted to see, indeed uses to be inconclusive. They got 1 definite case more and 8 probable ones over exactly the same sample; if limiting to the certain case, the variation is statistically little significant - as expected. Though, if comparing the Dec 2014 study with the June 2013 one, the increase is extremely significant. Since both samples are limited to 18 years age, the number of cancers in an equilibrium situation does not need to increase. Though, the observed increase is big (69ppm to 288ppm, from extrapolated 21 expected cases to 86 observed) and statistically strong. Small effects are difficult to observe, sure. For instance, the cancer increase in Corsica after Chernobyl was just a few cases more, which bad luck suffices to explain. But here we do have a number of cancers (86 cases!) that makes the measure accurate. No reference for the young Japanese population before the accident, or at least this is what I read. I wouldn't like to extrapolate the French study (predicting 8 cases instead of 86 observed), which may have completely different cancer criteria.That's why I prefer to compare the two vast studies after the accident.
-
Hello everybody and everyone... A December 2014 report about thyroid cancer saw 86 cases among 298,577 young people under 18 in the Fukushima prefecture. Lacking a reference report for Japanese people, I compared it with a French study http://www.invs.sante.fr/fr/content/download/7760/52112/version/1/file/bilan_cancer_thyroide.pdfpages 31-32 that saw 224 cases among 11 million French children under 14, that would extrapolate proportionally to 26ppm up to 18 years, or 8 expected cases amont 298,577 people. That discrepancy would be very significant, but The criteria of cancer may differ The populations differ genetically and culturally If I compare now with a June 2013 study in the Fukushima prefecture, it saw 12 cases over 174,000 young people. This seems a very significant increase. Even at 3 sigma above 12/174,000, the previous proportion then would have been 160ppm, extrapolating to 48 expected cases in the bigger December 2014 population, from which 86 cases are 5.5 sigma over ouch. Unless criteria have changed in the meantime. But it's the same population, the same context. I fear the early cases detected were indeed the beginning of a big peak. The argument by Japanese officials against a consequence of radioactivity was that such effects take longer to appear - but it's still coming. The good side is that thyroid cancer is very well cured. Though, it is also an indicator for other cancers that are harder to attribute to radioactivity. Finding the data on the Internet is difficult, as the topic is too passionate. On both sides: a report followed only two months after December 2014 just to conclude that the increase in two months wasn't significant - you guessed.
-
Understanding The Squirrel Cage Induction Motor.
Enthalpy replied to CasualKilla's topic in Engineering
Electric motors have varied designs, and books use to represent a very simplified vue of them... Because a real stator is a serious mess. Nice intention to help learning, but in my opinion, books should not occult the real world neither - introduced in a second step. Stator windings use to be split. This is important to make the motor run smoothly, and also to reduce the losses, especially at the rotor. Books tell "the sum of three phases make a rotating field" but obviously, the induction varies brutally from the right to the left sides of a slit. Splitting the winding over several slits makes the transitions smoother, so the rotor sees a smaller pulsating field as it crosses the slits. The slits (or the squirrel cage) are also skewed so the transition seen by the rotor spreads over some time. On the other hand, one slit uses to hoist winding paths lines of two phases, which doesn't help counting the slits... The number of conductors at the rotor is also chosen with a complicated ratio with the number of stator slits to further improve the smooth rotation. Every three-phase motor I've seen had split windings and skewed slits. It's conceptually more complicated, but efficiency and smooth run are so important that every designer uses them. In fact, split windings achieve so much with so little complication that it's admirable. Several schemes exist for split windings, and the number of slits changes accordingly, but expect many more slits than one per pole. A realistic picture for just three phases and possibly three pole pairs is there: http://en.wikipedia.org/wiki/Stator don't be afraid... If considering it with calm, good drawings and some sheets of clean paper, it's understandable. Then, you have single-phased induction motors that create a second phase using a capacitor, or using a closed conductor around one path of the inductor... So one should distinguish the supplied phase from the added one in that case. Others constructions exist. The induction motor zoo is quite varied, providing exceptions to every simple rule. A good book about motors and generators: Electric Machinery Fundamentals Stephen Chapman it does describe some real things beyond rotating vectors and has nice pictures. -
I confirm that many ideas applied at Fukushima dai-ichi were picked on the Internet. Some ideas that popped up at the plant were exotic enough (use a concrete pump lorry to pour water on the reactors, add a radio remote control to hydraulic cranes...) that other people improbably had the same one. The cover added to the #1 building resembles what Thomas described here, though it's permanent and doesn't use crane masts.. Over which path the ideas arrived at the plant is unclear to me. Several US entities helped a lot at Dai-ichi: the armed forces, the company that designed the reactors... I wouldn't exclude that these were culturally prone to adopt good ideas despite not being the authors, and were extremely reactive. I ignore the Japanese culture and how easily entities there adopt external ideas. And that many people read Internet forums is already clear. ---------- Again a thread here that isn't accessible through Google nor with the Internet address. Their supplied link fails. From the Engineering subforum list here, the links in the title and to the first page fails, the link to the second page works.
-
Heavy numerical tasks are well-known, so I've sought instead examples of databases to compare with the machines' capability. The worldwide eBay seems big: 200M items for sale, each one visited ~5 times a week, and users make supposedly 5 searches before viewing 5 items. That would make 1700 searches per second. Items have <200 bit properties and small attributes, plus a few words like price and dates, a 50 bytes title, a description text seldom searched estimated to 500 bytes long as a mean, and images not searcheable hence put on disks. The items base occupies 10GB (bits and numbers) plus 10GB (titles) plus 100GB (descriptions) - plus some disks. The PC-sized micromachine hosts all searcheable data in its 1TB Dram - some can even be replicated so not every chip must receive every request. Even if the program compared each query with each item, the 16 cores *4096 chips would still have 200 cycles per comparison. That's more than it takes, because the cores check 10 bits in one cycle and can rule out most items after one cycle. Not even the 7 words title takes 200 cycles of string instructions to parse and most often discard early. Then, precompute index tables to go faster, sure, especially for the description texts. Amazon and Alibaba must have similar search amounts, other sale sites and banks smaller ones. Puzzling idea, all eBay fitting in one single small box.
-
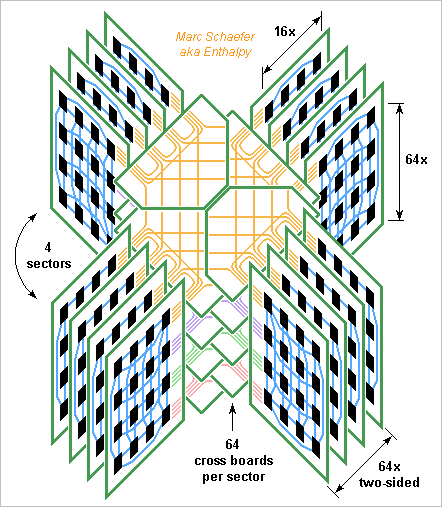
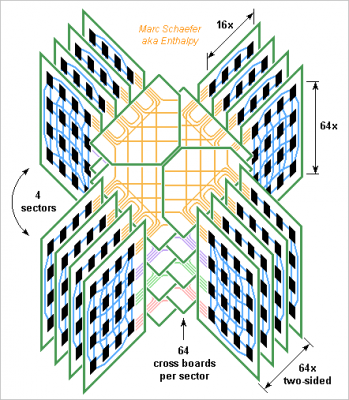
And this is the sketch of the machine. At 2PFlops (not TFlops! My mistake) it isn't the world's fastest (55PFlops in 4Q2014), but it's cleanly routed without cables, cute and compact, occupying just 2.2m*2.2m. If all sectors shared the cross boards, servicing one would let extract all computing boards first. I prefer these interleaved cross boards, where the cabinets hosting the computing boards can be separated. Strong adjustable struts hold the cross boards and cabinets at proper distance. Marc Schaefer, aka Enthalpy
-
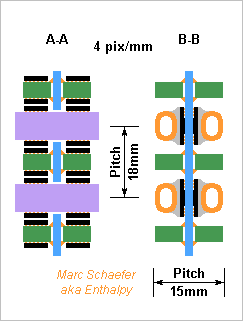
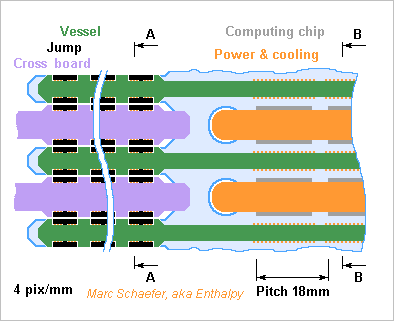
Here's the reasonably biggest hypercube routed by printed circuit boards without cables. At half a million 2GHz single-core chips, it consumes 0.9MW, offers 128TB and 34PB/s Dram, 1PB/s network through any equator, and 2TFlops on 64b - a database machine with the 16 core per chip and cascaded 10 logic instruction would offer 167*1015 logic operations per second. It has at most four cabinets of 64 vertical computing boards. Each computing board carries 64*16 computing chips per side. Each cabinet has 64 horizontal cross boards to interconnect the own computing boards and connect with the neighbour cabinet. The 256MB and 64b float chips measure 14mm*9mm as a Bga98 and have 19 link pairs. At 18mm*18mm pitch, they make a computing board slightly over 1m high and 0.55m long (0.16m interleaving, 0.29m computing, rest power and fluids). Vertical links take 3 board layers of 2 lines/mm plus repeaters every 0.25m for 20Gb/s, horizontal one take <1 layer. The alloyed copper cooling pipes distribute the current as well : 1V*51A per two-sided row, 3.3kW per board received as 48Vdc. The data vessels serve for adjacent rows of computing chips, with 1 input and 1 output vessel for 2*16 chips connected to 8 computing chips that are on neighbour boards on the hypercube. That's 256 links per 4mm*7mm vessel with ~20 signal layers plus ground and supply planes. 16 capacitive chips per vessel connect with the cross boards. Each cross board carries 2688 links within a cabinet. Using 300mm width and 1 line/mm (for 2 repeaters per metre at 20Gb/s) this takes 9+ signal layers and as many grounds. It also carries 4096 links to the homologue cross board in the cabinets at its right and left, which takes 3+3 signal layers and 3 grounds; this sketch should follow. Capacitive chips interconnect the cross boards between the cabinets; their package can be bigger for the cross boards to ease routing. The cross boards also are 1m+ big. The worst latency between hypercube neighbours in 13ns, similar to the Dram. Through the worst hypercube diagonal, the latency is ~60ns without collisions: as much as transmitting 120 bytes. Marc Schaefer, aka Enthalpy
-
Tough clear plastic film recommendations, please ?
Enthalpy replied to Externet's topic in Engineering
Thanks JC! I still have one little doubt: the gardening PE and PP films use to be black or at least dark. Could a UV absorber be added intentionally to protect the polymer's depth and allow to last longer? (They say it's a role of carbon black in tyres) That would explain that they last 3 years while clear (and thinner) shopping bags are quickly ruined. The trick wouldn't be applicable to Solar energy. Slightly off-topic but fun: as an eclipse is expected in Northern Europe, "some people" explain it needs careful preparation by the electricity providers because allegedly 6% of the European electricity is solar. The eclipse is centered on the Faroe and Spitzberg islands - I just doubt someone installed giant photovoltaic plants near Longyearbyen to supply Spain with electricity. -
When molten, gallium permits the classical electromagnetism experiments without the risks brought by mercury.
-
Is Wikipedia currently credible?
Enthalpy replied to MWresearch's topic in Modern and Theoretical Physics
Sometimes Wiki is botched, even intentionally, and isnt' corrected for months or years. This is uncommon but does happen. On the other hand, any encyclopaedia contains mistakes, any peer-reviewed journal as well, and Wiki belongs to the good ones. One nice feature of free editing is that, when an assertion is debated (example: minimum harmful radiation dose versus Linear-No-Threshold), generally someone lets it know on Wiki - while single-sourced websites and papers won't. I'm a bit uneasy with the notion of "credible source". Readers should decide to believe a thesis, not an author nor a source. Wiki isn't generally cited in academic papers as they prefer to cite other research papers, and a link to Wiki might be considered with little confidence there. But on a scientific forum, a link to Wiki is fantastic as it tells easily "this is what I'm speaking bout", and as an encyclopaedia, it uses to be an excellent introduction to a topic for non-specialists. -
Quantum Entanglement (split from electron spin)
Enthalpy replied to MirceaKitsune's topic in Quantum Theory
Acting on one particle will leave the other unchanged. Entanglement is used in secure datacomms, but as a way to detect if the channel has been tampered. -
Maybe the new cascaded logic operation deserves an illustrative example. Imagine a seller proposes many graphic cards memorized in a database where some attributes are stored as bit fields: enum { Ddr=0x0, Ddr2=0x1, Ddr3=0x2, Ddr5=0x3, Gddr3=0x4, Gddr4=0x5, Gddr5=0x6, Amd=0x0, nVidia=0x8, Used=0x00, Refurbished=0x10, NewWithoutBox=0x20, NewInBox=0x30, Agp=0x00, PciE=0x40, OnlyMonitor=0x000, VideoIn=0x080, VideoOut=0x100, VideoInOut=0x180, NoLed=0x000, GreenLed=0x200, RedLed=0x400, YellowLed=0x600, Cash=0x0000, CreditCard=0x0800, Transfer=0x1000, Cheque=0x1800 }; and a customer seeks only such items: only Gddr5 => bits 1 and 2 only nVidia => bit 3 new or refurbished => bits 4 or 5 only PciE => bit 6 video in and out => bits 7 and 8 led colour => don't care credit card or transfer => bits 11 xor 12 the the database runtime reads to register 2 the current item's attributes fills the register 5 with the source bits positions (coded on 6 bits each) 1 2 3 4 5 6 7 8 11 12 fills the register 8 with the operations (coded on 4 bits each) push and and push or chain and and and and push xor chain and nop nop then performs CascLog R2, R5, R8, R13 and checks in R13 if the current item satisfies the customer's wish. This differs slightly from the previously suggested operation with immediate bit positions and operations. It offers runtime flexibility (to adapt to the customer's wish here), operates on 10 bits at once, and can leave several result bits for following instructions. Marc Schaefer, aka Enthalpy
-
Tough clear plastic film recommendations, please ?
Enthalpy replied to Externet's topic in Engineering
PE and PP are the cheapest, but do they resist sunlight for a substantial duration? Shopping bags for instance destroy within one summer, and I have big doubts about PET as well. PC and PMMA at least are known to survive sunlight. -
When molten, it dissolves other metals. Aluminium wrapfoil maybe? It's also claimed to make steel brittle even if added in small amount at the surface and be consequently used for sabotage; I've no opinion about that. Some gallium eutectics are liquid at room temperature, Galinstan (Ga-In-Sn) is famous but Ga-In suffices already. Does liquid gallium take less room than solid one?
-
Need vaues for critical conditions of Uranium 235
Enthalpy replied to MWresearch's topic in Modern and Theoretical Physics
Nukes were difficult 70 years ago. Technology has progressed meanwhile, as well as the general knowledge, and worse, materials are available. Who knows what Daesh finds in Syria and Iraq, as accumulated by Saddam and the others? They have already found combat gas and components to make them, and Iraq had acquired nuclear materials. In addition, nuclear material can be purchased presently - fundamental difference with 1940. As for Daesh, they are capable of making Internet attacks, and after months of bombing by the US and allies, they stay and gain terrain occasionally. What information is available from the best sources to the best specialists isn't neither what tinkerers know or can find, especially in a country destroyed by war, under embargo and from which the scientists have fled. The questions raised on a chemistry forum were obvious for any student, yet they related closely to the combat gas later used by Assad's regime, and would improbably have been needed for an other use. So information even far below the best knowledge can make a difference. Then you should distinguish between the sought effect of nuclear weapons. One that fits is a rocket transported by a small combat aircraft and destroys a city is difficult, one that fizzles where a group has placed it is far easier, and is enough to terrorize a city and deter a government. In fact, I'd like nuke scientists to think at ways to prevent such an attack. Government programs try to intercept incoming missiles, which is irrelevant. The two bombs that destroyed cities did not travel on missiles, the next one may well travel by container ship. Notice I'm by no means suggesting this is the intent here. But remember that many people read forum discussions, not just identified forum members. -
Book says 16 bits is equivalent to 32,678 bytes
Enthalpy replied to DylsexicChciken's topic in Computer Science
Is there any machine where address offsets are understood as signed? I know none up to now. And since the Ram size often differs from the maximum addressable space, it matters. -
This example is a personal number-crunching machine with cross boards that fits on a desktop. It has the size of a Pc, the dissipation of an electric heater, is air-cooled, and can connect to a Pc host via one or two Pci-E cards running external cables. Each computing chip bears one 64b float Cpu that multiplies-adds at 1GHz - for power efficiency - and 256MiB of Dram delivering 32GB/s. The 9mm*11.5mm Bga78 packages occupy 30mm*20mm pitch. Each vertical computing board comprises 16*4*2=128 computing chips. They're 500mm tall, 150mm long, spaced by 15mm. Less than 2 layers route 160 vertical links, less than 1 the 64 horizontal ones. 1 ground plane and 1 supply plane distribute 64A*0.8V from the board's insertion edge where the local converter receives 48Vdc for instance. 32 computing boards make a 500mm*500mm*250mm machine. The 4096 nodes dissipate 1700W, mean 0.2m/s air flow through 500mm*500mm cools them. One in and one out data vessels connect each row of 4*2 computing chips to their homologues at 5 neighbour computing boards. Each vessel carries 40 links in 5mm height and 4+ signal layers plus grounds and supplies. 3 capacitive modules pass data between each vessel and each cross board. 16 cross boards interconnect cleanly the 32 computing boards as on the 01 February 2015 sketch. A cross board passes 352 links at the densest section, so 60mm width suffice with 3+ signal layers plus ground and supply. The cross boards could have computing boards on two or four sides, but the bigger machine heat too much for a desktop, and I prefer bigger computing boards then. Total 8.2TFlops aren't much more than one Tesla Pci-E card (1.3TFlops on 64b) but the rest is: 131TB/s Dram instead of 0.25 feed the Cpus for easy algorithms 1TiB Dram instead of 6GB mesh the Earth at 10 numbers per element with 200m pitch rather than 2.6km, or mesh an 80m*80m*40m airliner flow with 30mm pitch rather than 150mm. A disk per board, or few flash chips per Cpu, can store slow data, say at each time step of the simulation. At 20Gb/s, the network transmits 4TB/s through any equator. Its latency is 6ns (6 Cpu cycles, less than the Dram) if the chips are good and it carries one word in 4ns more, one 512B Dram access in 262 cycles - so the scaled indexed and butterfly access to Dram at a remote chip is interesting. And even if a node requested individual remote Dram floats randomly over one link, 32b in 15+6+2 cycles would feed two Macc per cycle for a 2048-point Fft. Marc Schaefer, aka Enthalpy ============================================ The same box makes a small cute 1TB database machine - or an inference, Prolog or Lisp engine, or a web server. Though, this use emphasizes other capabilities: Quick floating point is secondary, even integer multiplies aren't so frequent; snappy random access to the whole Dram is paramount; unpredicted branches must bring minimal penalty; logic operations occur often. Different versions of the computing chips, meant as float-cruncher or instead as database runner etc, can run the same executables but optimize the hardware differently: No 64b*64b float multiplier. A 1b*64b multiplier, or 4b*16b, takes 64 times less power. But cheap provision for exponent, denormalization, renormalization, conversion, division step is welcome. The 64b instructions run, just slower. We could have raised the clock, widened the words, have many scalar integer execution units... But: I prefer to keep 1GHz, shorten the pipeline for quick branches, and have 16 cores per chip (not 64 as the sequencer and registers draw power). The 256MiB Dram cut in 16 must be ~16 times faster, or 2ns access. The access and cache width shrink to 8 words. A tiny Bga98 package limits to 2 links in each direction between two chips, shared among the cores, easy for the boards. Bigger packages would occupy more area to no benefit. Fortunately, a database doesn't need much network throughput. Faster logic operations cost little hardware and opcodes which are useful on any machine: several logic registers, destination tables, compare-and-branch, compare-and-store, compare-and-combine, compare-combine-and-branch... µops fusion achieve it anyway, but opcodes that simplify the sequencer are welcome. One cycle per logic operation is a perfect waste. Programmable logic could combine tens of bits per cycle to filter database items; though, its configuration takes time even if loaded from the Dram, and this at each context switching, not so good. As a compromise, I suggest a cascade logic operation from an implicit source register to an implicit destination register working stackwise: And, Or, Eq, Gt, Lt and their complements, Push, Swap, DuplicateOrNop - coded on 4 bits, the source bit position on 6 bits, this 5 times in a 64b instruction. The operations and source bits can also be read from a register and the source and destination registers be more flexible. Feel free to execute several such adjacent instructions at once. Useful on many machines. Some string support wouldn't hurt any machine, especially the search of a variable number of bytes in a register at any byte shift. A fast stack for Lisp is nice everywhere. In the database or AI version, this micro machine offers 65*106 Mips and 320*1012 logic operations per second. It could dumb-parse the 1TB in 2ms, but indexing will naturally gain a lot. Marc Schaefer, aka Enthalpy
-
Tough clear plastic film recommendations, please ?
Enthalpy replied to Externet's topic in Engineering
Very few plastics are transparent nor even translucent. Very few plastics survive sunlight. Glass would be my choice, much preferred over plastics. Polycarbonate yes, Pmma also but it's more brittle. You might check whether PET and PP resist sunlight. Sadly, PP is transparent to thermal infrared. Some polyvinyl can be translucent but I fear they won't last. Few more are translucent like FEP or PMP but very expensive. Instead of a different material, I'd suggest to optimize the shape. Similar to a honeycomb sandwich, or more easily an extruded profile, it will give you more strength and stiffness from less mass and insulate much better. Already available on the market, example http://www.design-composite.com/index.php/en/produkte/architektur-design/clearpep A multistage custm-made extrusion would insulate even better, like there http://www.scienceforums.net/topic/85785-drop-tube-elements/#entry828414 antireflective coating wouldn't be bad if feasible. Mma is a perfect glue for Pmma, others exist for PC. -
Maybe a parallel would make modulo and signed arithmetic clearer. Imagine that we count hours from 0 to 23 beginning at midnight - and forget the minutes altogether. This is cyclic arithmetic, that is, 23+2=1 instead of 25. We compute modulo 24 just like a 16-bit machine computes modulo 65536. Now, we could prefer to count the afternoon hours as the remaining time until midnight. 1PM would be -11, 6PM is -6, 11PM is -1. This is just the conventional value we attribute to the numbers, which are still represented by the same positions of pebbles on the ground, hand angles on the watch, bits combinations in the machine. We have just invented signed numbers. Signed hours run now, just by convention, from -12 to +11, while unsigned hours ran between 0 and 23. The original question subtracted one from zero. When time is unsigned, one hour before midnight is 23. When time is signed, it is -1 hour. Whether we consider it 23 or -1 depends on how we interpret the same hand angles on the watch. In a computer too, it's the same combination of bits that is interpreted as unsigned or signed integer. And on a 16 bit machine, "one less than zero" means "one less than 65536" or 65535, which is the biggest number that can be represented as unsigned integer, with all bits at 1. If interpreted as a signed integer, this combination of bits means -1.
-
Need vaues for critical conditions of Uranium 235
Enthalpy replied to MWresearch's topic in Modern and Theoretical Physics
"Atomic physics" does not mean "nuclear physics", and nuclear physics encompasses many fields, most of which don't relate with bombs nor chain reactions. So you don't need to kidnap Swansont for your project, we'd happily keep him here... Since uranium enrichment becomes easier over time, and fissile material can be acquired the design of a bomb must be less obvious than the available descriptions an ineffective bomb is already worrying enough many different people read forums, not only the participants several information requests on an other forum matched closely chemical weapons later used by the Assad regime maybe some members here find unreasonable to add information on the Internet. -
Understanding The Squirrel Cage Induction Motor.
Enthalpy replied to CasualKilla's topic in Engineering
As the cage resistance drops, the best efficiency improves, but it happens at a smaller slip frequency (difference to the synchronous frequency). At too big slip frequency, the available torque decreases when the cage resistance decreases. At the extreme case, a perfectly conductive cage (remember there are type I and type II superconductors, type I aren't useable for most applications, type II have a residual resistance) is perfectly unuseable, because it gives zero mean torque at any nonzero slip, so the squirrel cage motor doesn't start, it cogs only. You would have to freeze a non-zero flux in the rotor, which is possible with geometrically separated conductors like a cage, and also with a continuous type II material, but then this is a synchronous machine. Also, permanent magnets do it as well - the benefit of a synchronous superconductor rotor being the higher inductance and coercitive field. Then, at a synchronous machine, you can have a superconductive stator, which lets the coolant flow more easily than the rotor, and may combine with permanent magnets at the rotor. This combination is meaningful for slowly rotating motors like boat propeller pods. Though, my electrostatic motor-alternator will compete with them once someone develops it, search for: "electrostatic alternator" "Marc Schaefer" Maybe superconducting motors will emerge some day, maybe not. They must replace already good solutions, a hard job for any innovation. My feeling is that people shouldn't try to adapt to superconductors designs that have been optimized for copper, but instead search completely new designs. -
How do you prevent eddy currents in a transformer?
Enthalpy replied to Mr. Astrophysicist's topic in Engineering
Most forum members here knew the "laminate" answer, and so did the original poster, so maybe t's more useful if I bring some elements that are less universally known - and my apologies in advance to all who know them already. Transformer steel contains silicon. Despite reducing the saturation induction, silicon is very useful to increase the resistivity of steel hence reduce the eddy currents. It's also one convenient means to deoxidize the steel, which reduces the coercitive field hence the hysteresis losses. Lamination thickness acts on the eddy current losses squared, but so does the frequency also, and the stray capacitance of the laminations' insulating oxide would let capacitive current pass anyway, so above some 400Hz to 10kHz, the game with thinner laminations is over. The usual next step is iron powder, which is easily finer than a lamination. The powder is oxidizer superficially to insulate and then sintered. Though, the iron filling factor is worse, dropping the saturation induction, and since oxide layers are in all direction, the induction must cross them and the permability drops, so iron powder is used where laminations can't go well, in the kHz range. Above iron powder, and up to coreless inductances in the100MHz+, is the domain of ferrite. The material itself (Fe, O, and variable amounts of Mn and Zn, for the most common ones) resembles more a ceramic than a metal: very brittle, and a high resisitivity that reduces eddy currents without having to interrupt them with an insulator. Though, I used once the market's best ferrite core for antennas (made by Philips then), and this one had longitudinal slits, with dents in its cross-section, to reduce the eddy currents further - it was damned brittle. I needed Litz (=braided) wire for the windings, a good insulator between the ferrite and the winding, a decent insulator (no Pvc) on the terminal wires, and then I got Q=400 at 457kHz, wow. With that ferrite antenna, a bandwidth <1Hz and many more optimizations, I reached a sensitivity of -170dBm and made the equivalent of an avalanche transceiver http://en.wikipedia.org/wiki/Avalanche_transceiver but with 110m range instead of <20m, that is, a power improvement of 30,000+. Eddy currents also appear in the windings, typically at 10kHz-1MHz (above, the current doesn't penetrate the wire anyway, so the effect has a different name). The standard answer is to use braided (Litz) wire. Even at lower frequencies, some transformers with a low voltage side must use one single turn of copper, as a foil rather than a wire then. Any (leakage) induction through this foil creates huge eddy currents because of its width, so the answer attempt (it's imperfect) is to split the other winding in two and put one half nearer to the core than the foil winding and the other half outside the foil. By symmetry, the leakage induction is minimized. At one inductor for 20kHz, with a cut U core of winded steel, I had an intended gap of several mm. I suspected the lateral spread of the flux above and below the gap to create losses in the laminations since they were not parallel to the induction there. I added a copper foil right around the core at the gap, making 1.5 turn but insulated, and made the winding again. My intention was to guide the flux with the foil to stay parallel at the gap; whether it worked that way or differently, it did reduce the losses. I must have forgotten some more methods.